Publications
Papers published at top conferences and journals.
ACM MM
2023 2 papers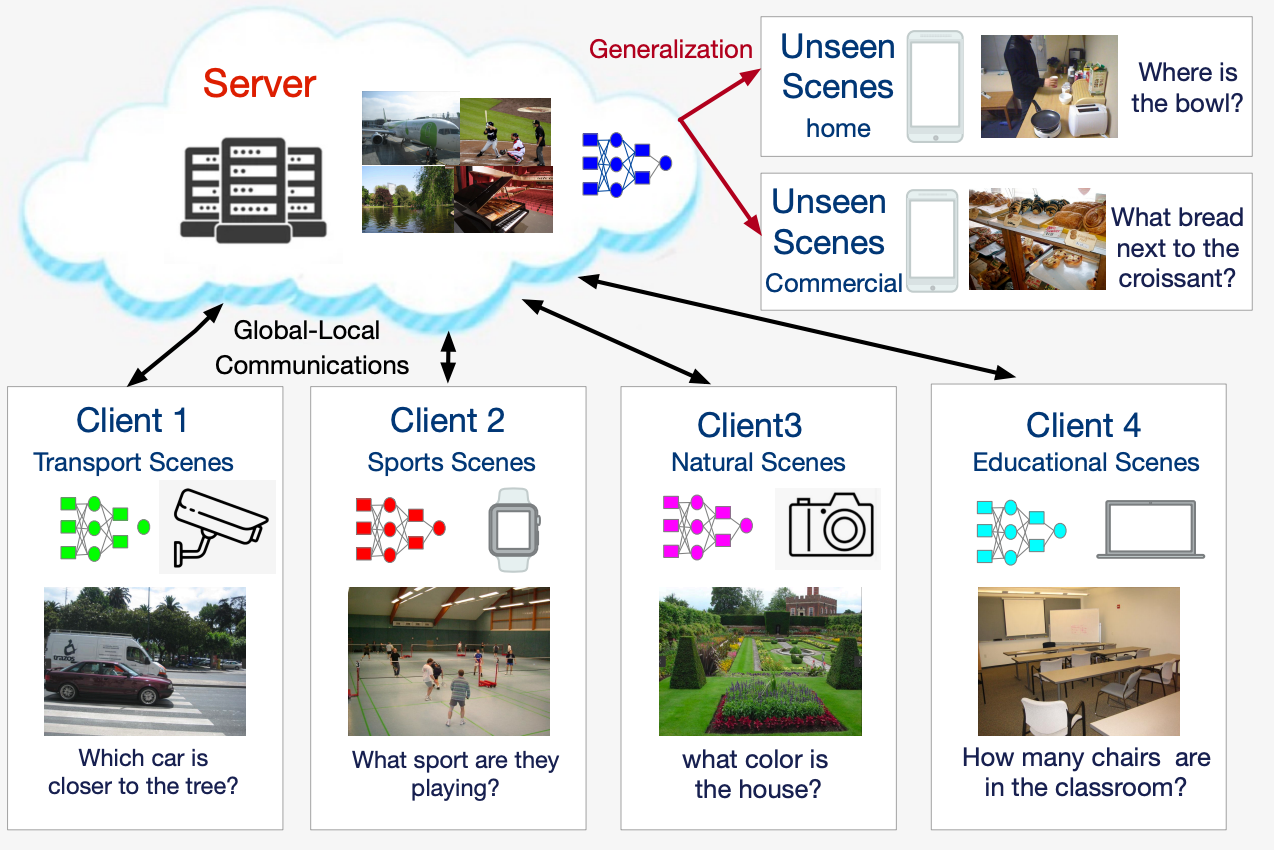
CVPR
2023 7 papers

AutoLabel: CLIP-based framework for Open-set Video Domain Adaptation




Novel Class Discovery for 3D Point Cloud Semantic Segmentation

Quantum Multi-Model Fitting
ICASSP
2023 1 paper
ICCV
2023 11 papers
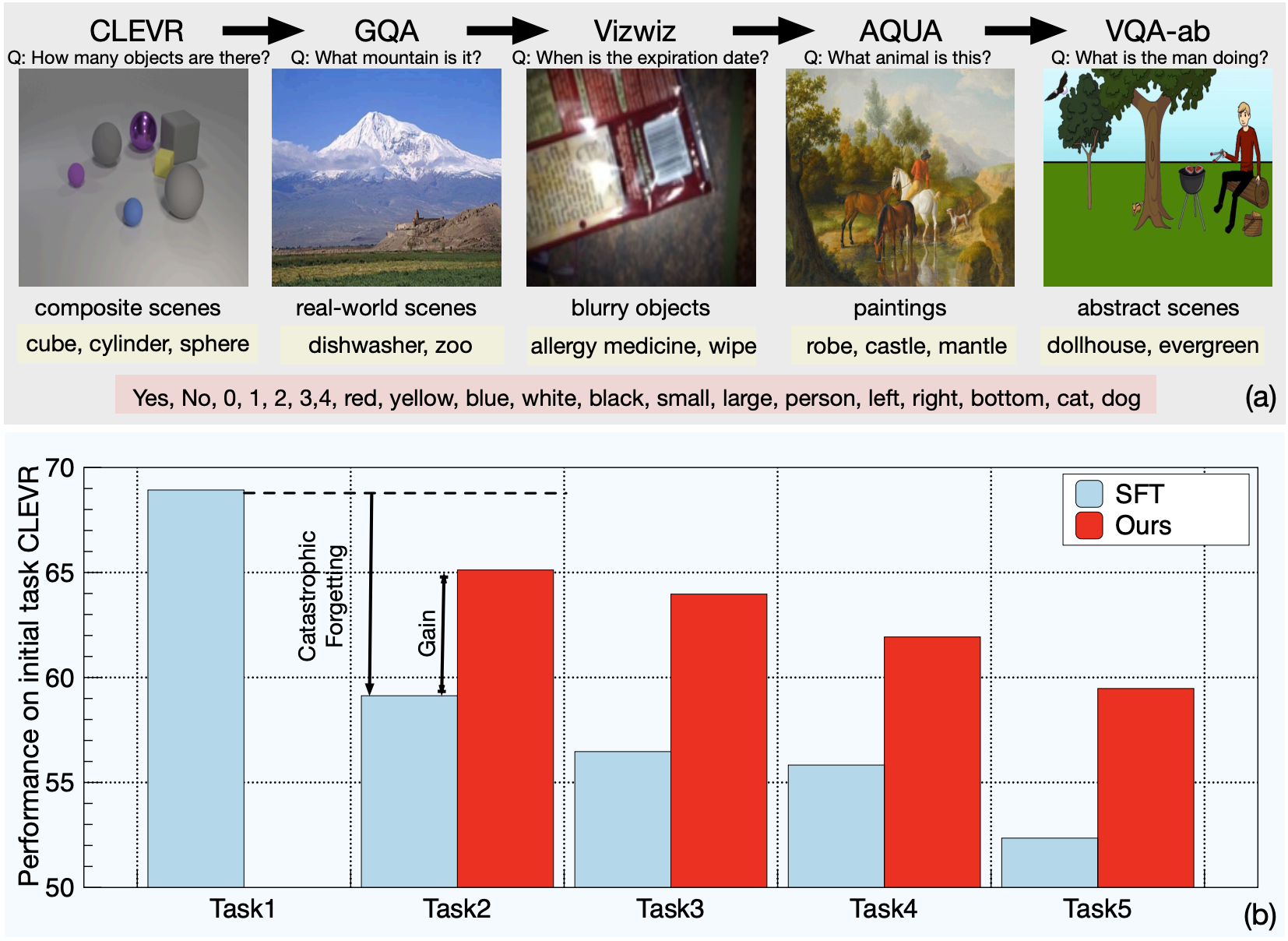
A soft nearest-neighbor framework for continual semi-supervised learning


Image-free Classifier Injection for Zero-Shot Classification

Iterative Superquadric Recomposition of 3D Objects from Multiple Views


On the Effectiveness of LayerNorm Tuning for Continual Learning in Vision Transformers

PDiscoNet: Semantically consistent part discovery for fine-grained recognition

ProbVLM: Probabilistic Adapter for Frozen Vison-Language Models

StylerDALLE: Language-Guided Style Transfer Using a Vector-Quantized Tokenizer of a Large-Scale Generative Model
The Unreasonable Effectiveness of Large Language-Vision Models for Source-free Video Domain Adaptation

Walking Your LiDOG: A Journey Through Multiple Domains for LiDAR Semantic Segmentation
ICIAP
2023 1 paper
Unsupervised Video Anomaly Detection with Diffusion Models Conditioned on Compact Motion Representations