Research Interests
Computer Vision
Papers (25)
2026
From Weights to Concepts: Data-Free Interpretability of CLIP via Singular Vector Decomposition
Francesco Gentile, Nicola Dall'Asen, Francesco Tonini, Massimiliano Mancini, Lorenzo Vaquero, Elisa Ricci
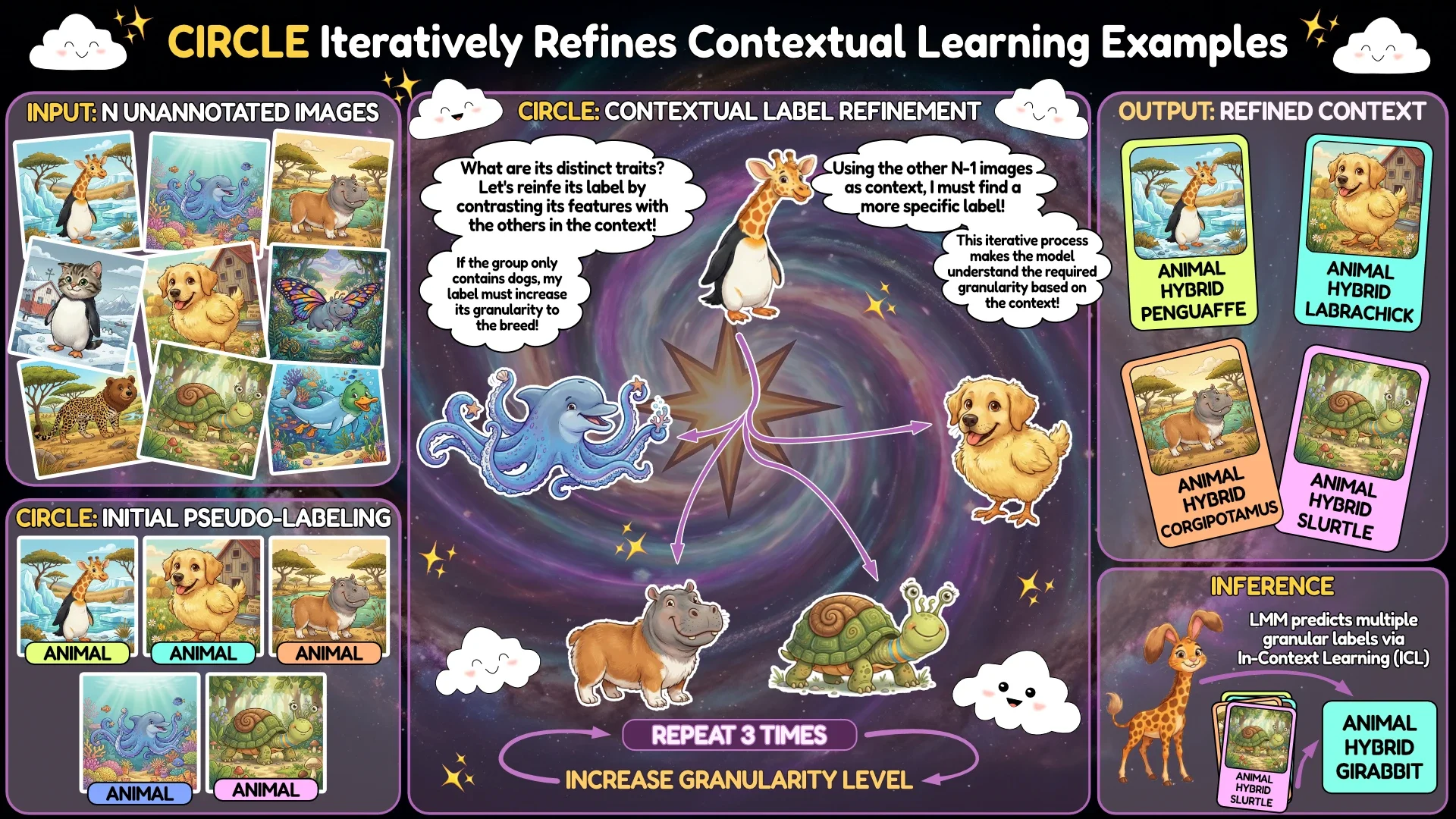
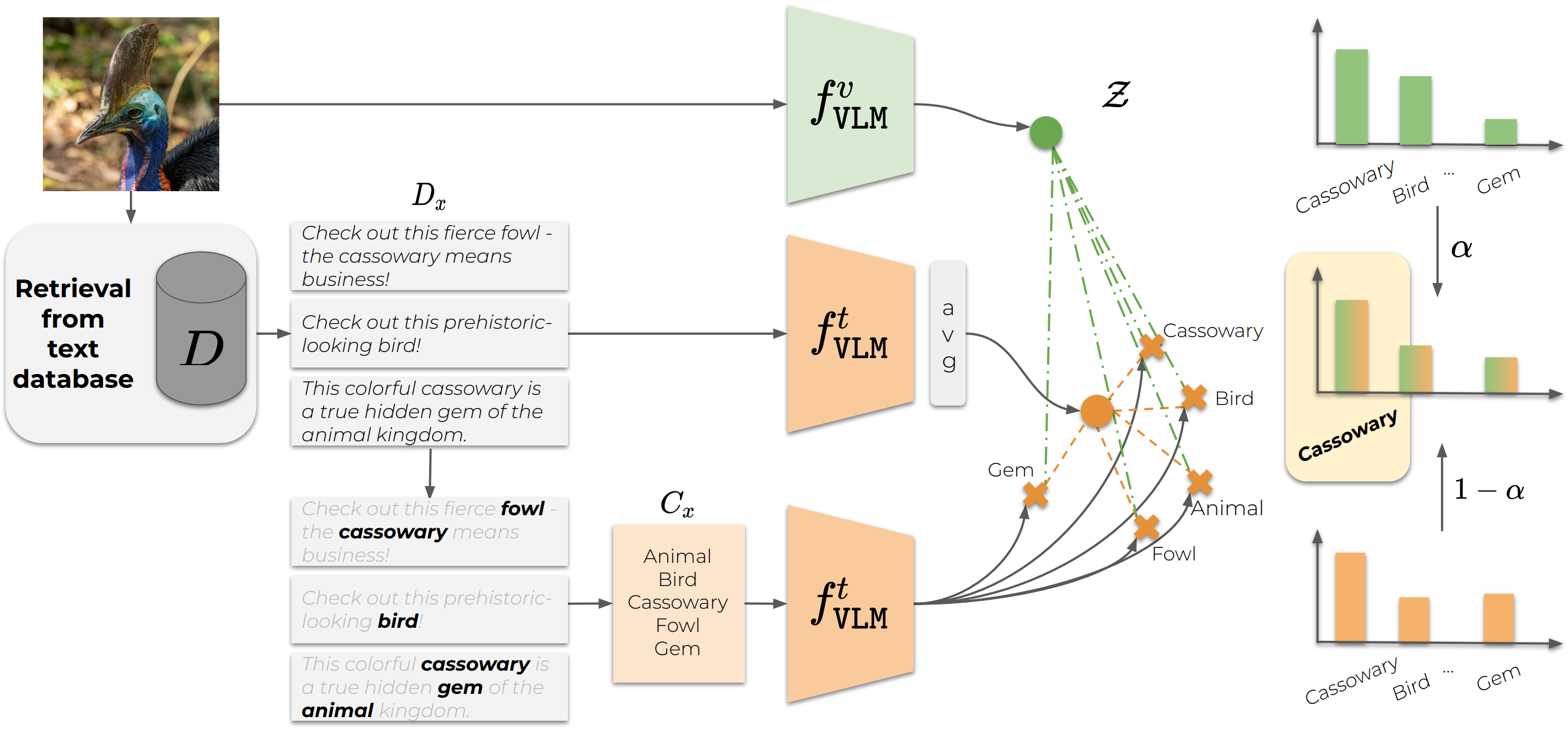
Large Multimodal Models as General In-Context Classifiers
SEM: Sparse Embedding Modulation for Post-Hoc Debiasing of Vision-Language Models
Quentin Guimard, Federico Bartsch, Simone Caldarella, Rahaf Aljundi, Elisa Ricci, Massimiliano Mancini
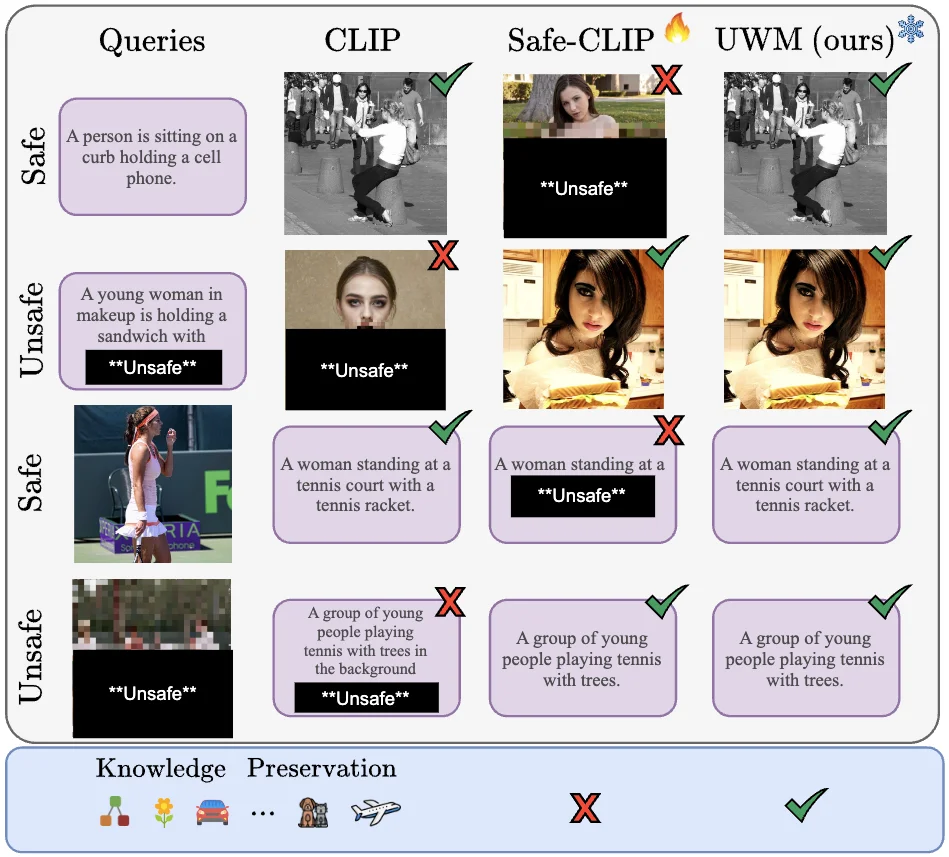
Safe Vision-Language Models via Unsafe Weights Manipulation
2025
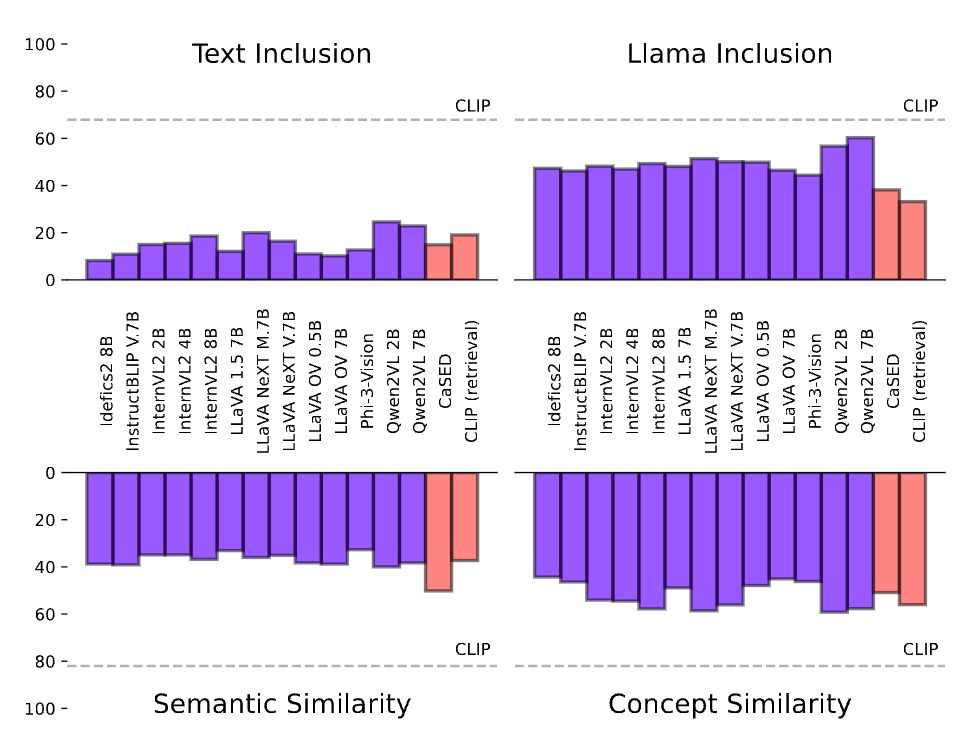
On Large Multimodal Models as Open-World Image Classifiers
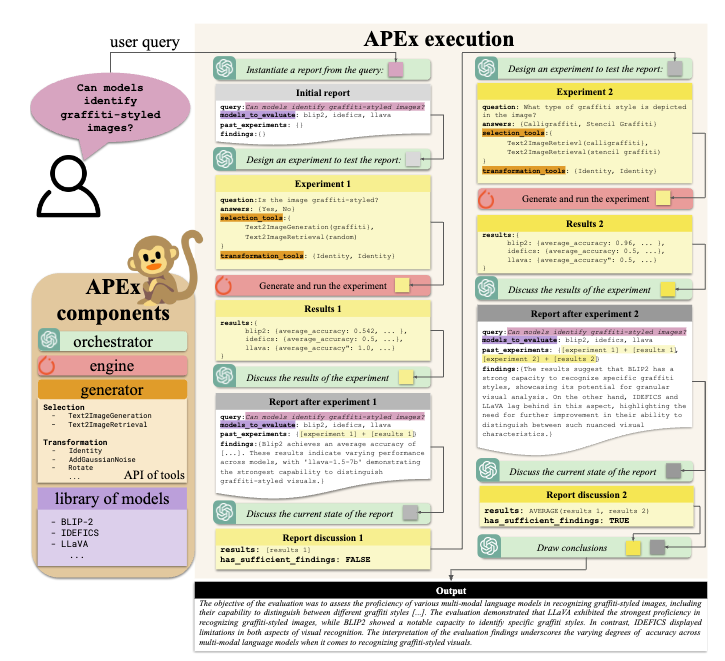
Automatic benchmarking of large multimodal models via iterative experiment programming
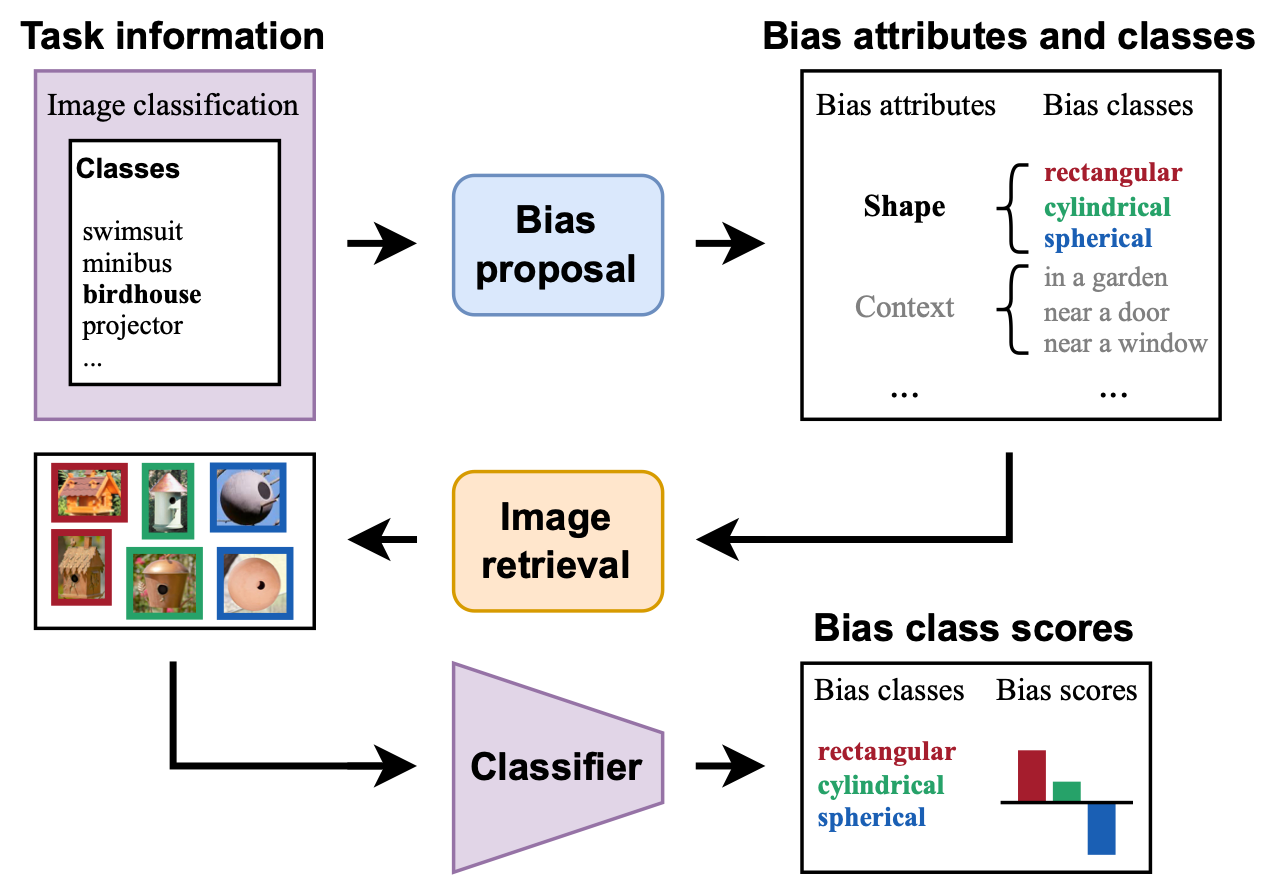
Classifier-to-Bias: Toward Unsupervised Automatic Bias Detection for Visual Classifiers

Highlight
Compositional Caching for Training-free Open-vocabulary Attribute Detection
Highlight
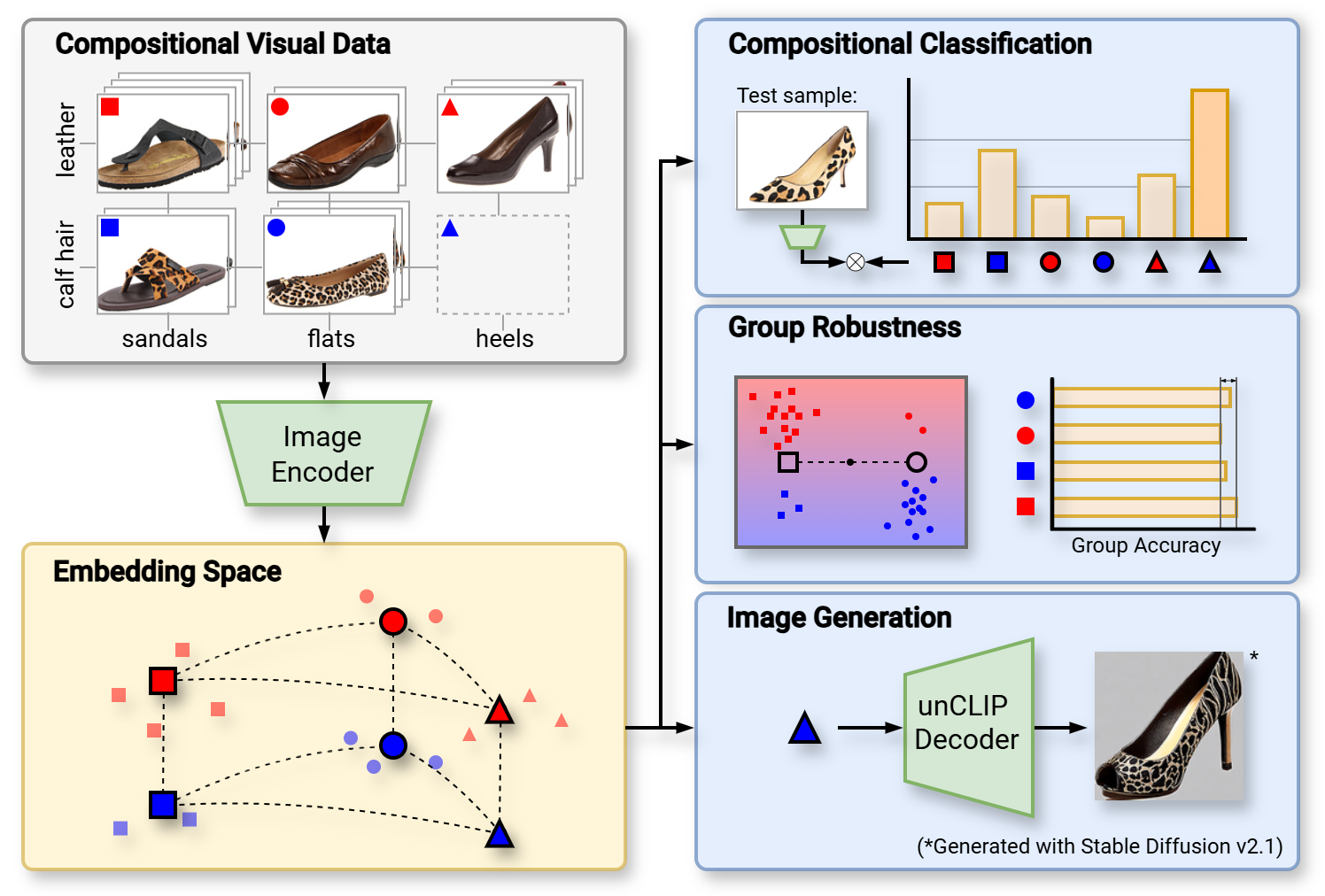
Not Only Text: Exploring Compositionality of Visual Representations in Vision-Language Models

3D Part Segmentation via Geometric Aggregation of 2D Visual Features
GradBias: Unveiling Word Influence on Bias in Text-to-Image Generative Models
Moreno D’Incà, Elia Peruzzo, Massimiliano Mancini, Xingqian Xu, Humphrey Shi, Nicu Sebe

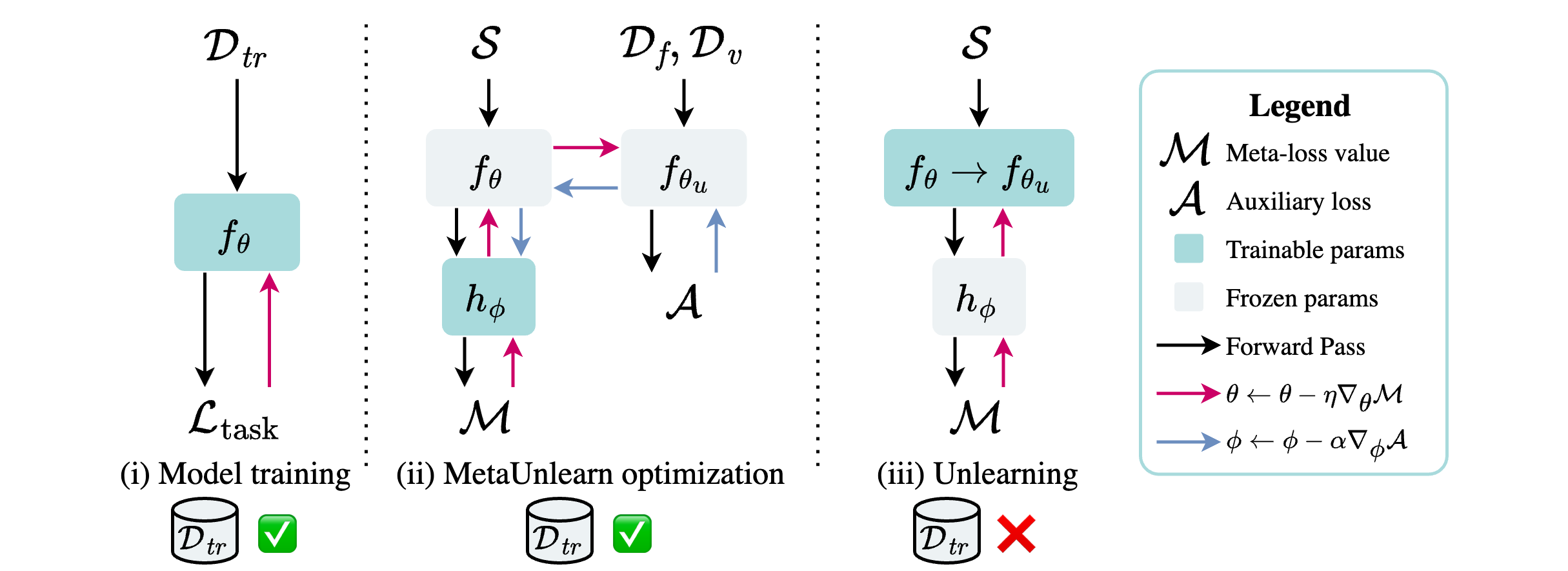
Group-robust Machine Unlearning
Unlearning Personal Data from a Single Image
2024
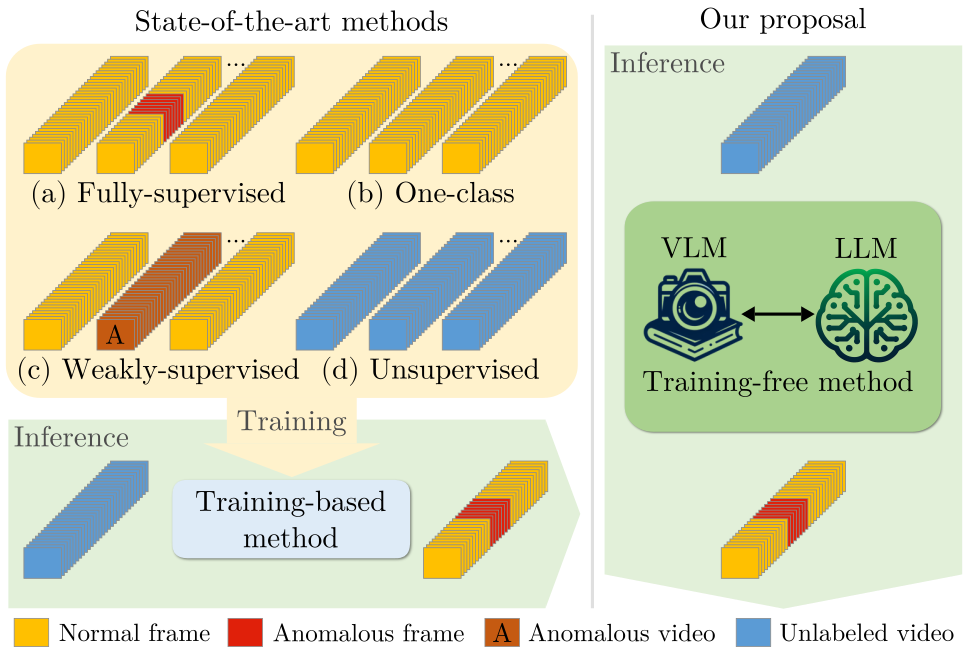
Harnessing Large Language Models for Training-free Video Anomaly Detection
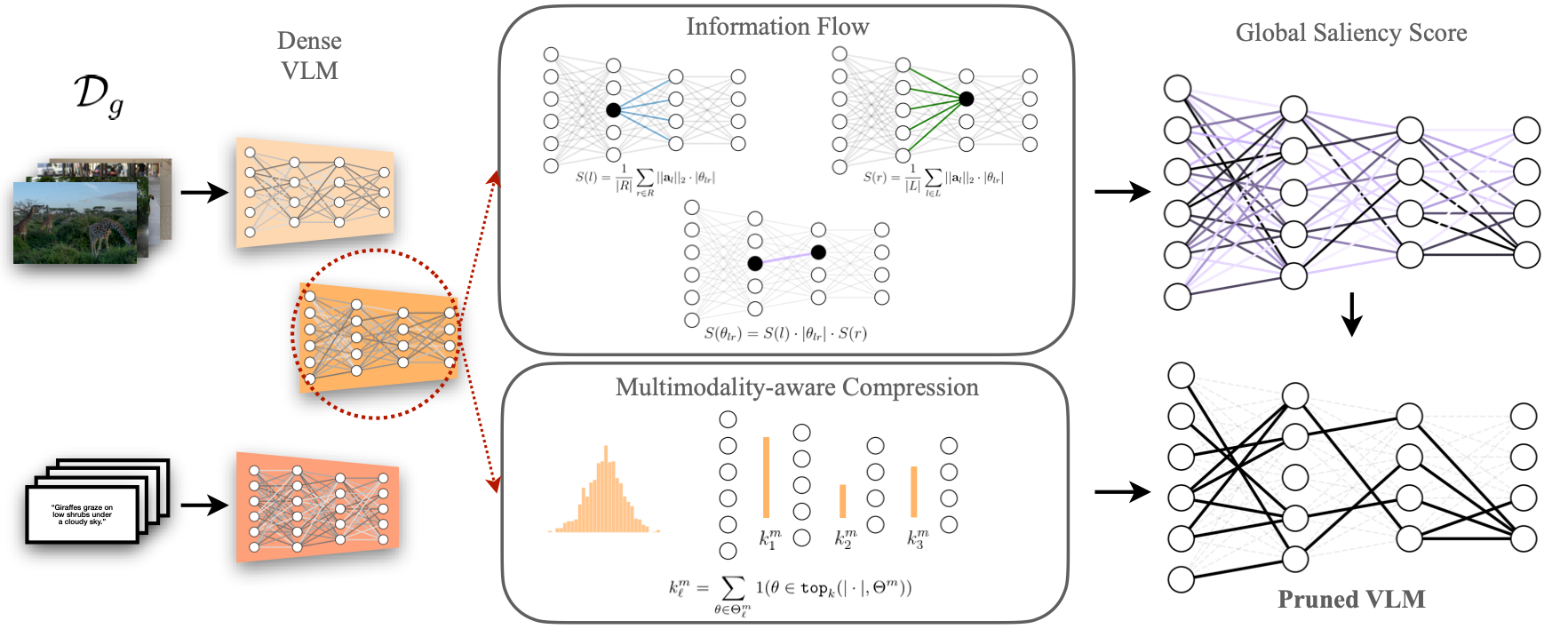
MULTIFLOW: Shifting Towards Task-Agnostic Vision-Language Pruning
Highlight
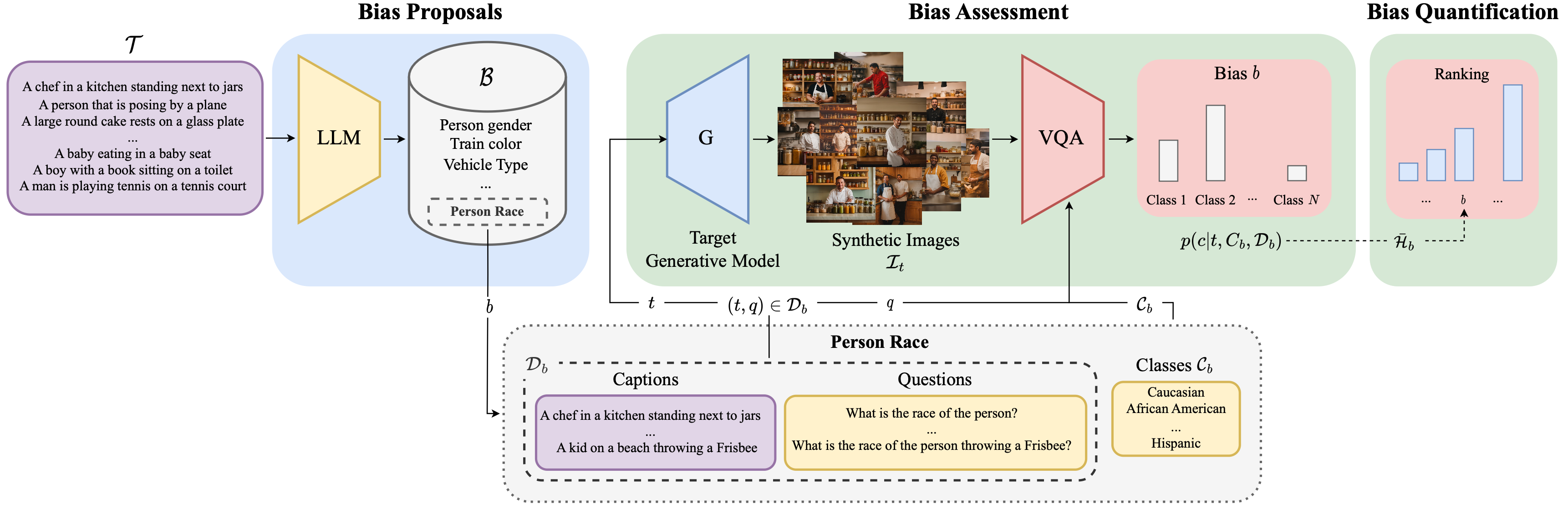
OpenBias: Open-set Bias Detection in Text-to-Image Generative Models
Moreno D'Incà, Elia Peruzzo, Massimiliano Mancini, Dejia Xu, Vidit Goel, Xingqian Xu, Zhangyang Wang, Humphrey Shi, Nicu Sebe
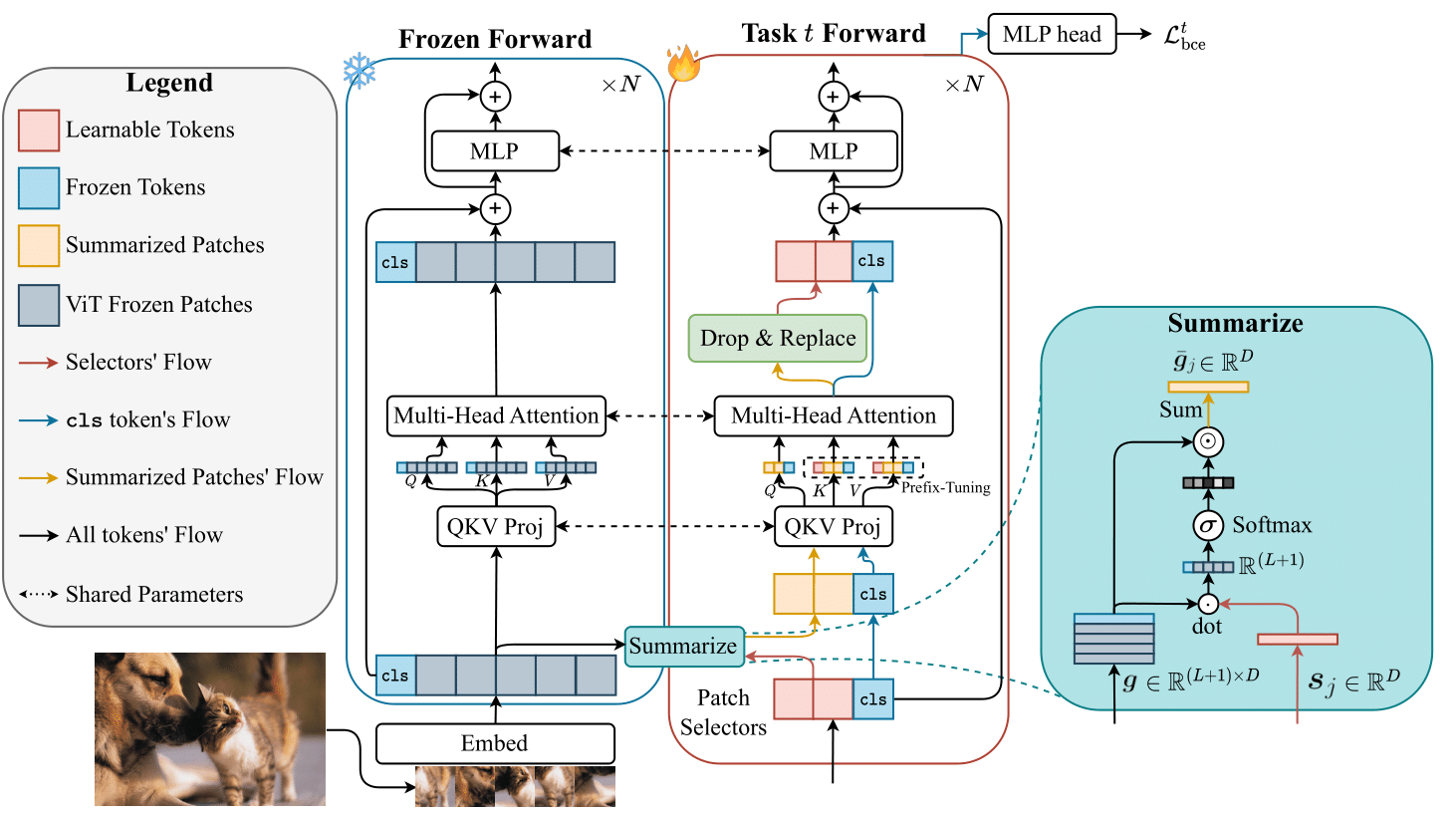
Less is more: Summarizing Patch Tokens for efficient Multi-Label Class-Incremental Learning

Frustratingly Easy Test-Time Adaptation of Vision-Language Models
2023
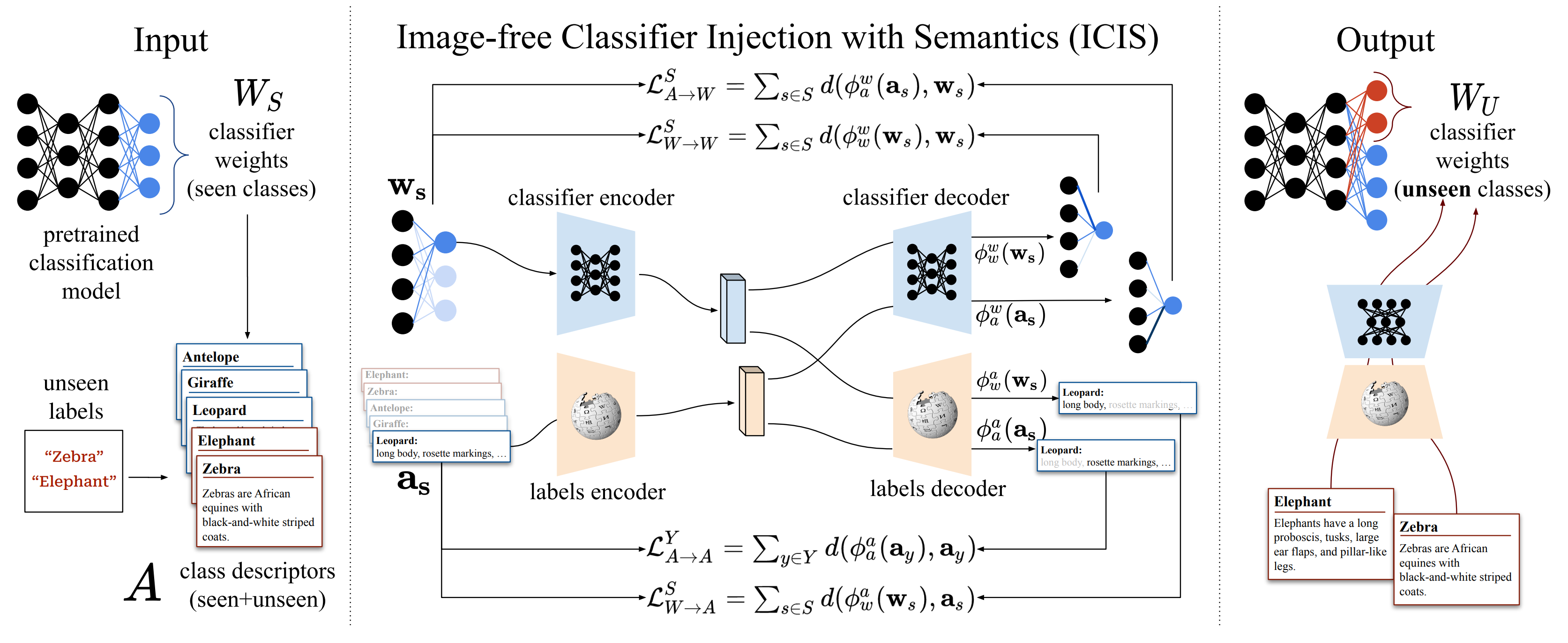
Image-free Classifier Injection for Zero-Shot Classification
Anders Christensen, Massimiliano Mancini, Almut Sophia Koepke, Ole Winther
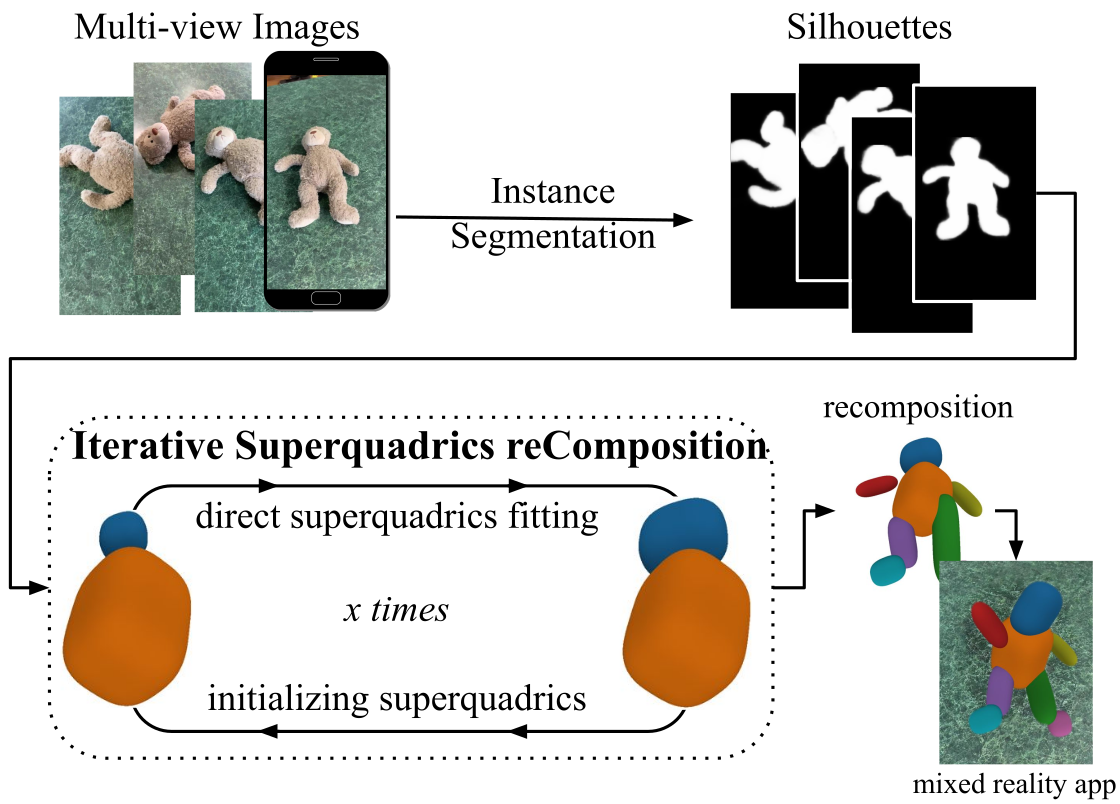
Iterative Superquadric Recomposition of 3D Objects from Multiple Views
Stephan Alaniz, Massimiliano Mancini
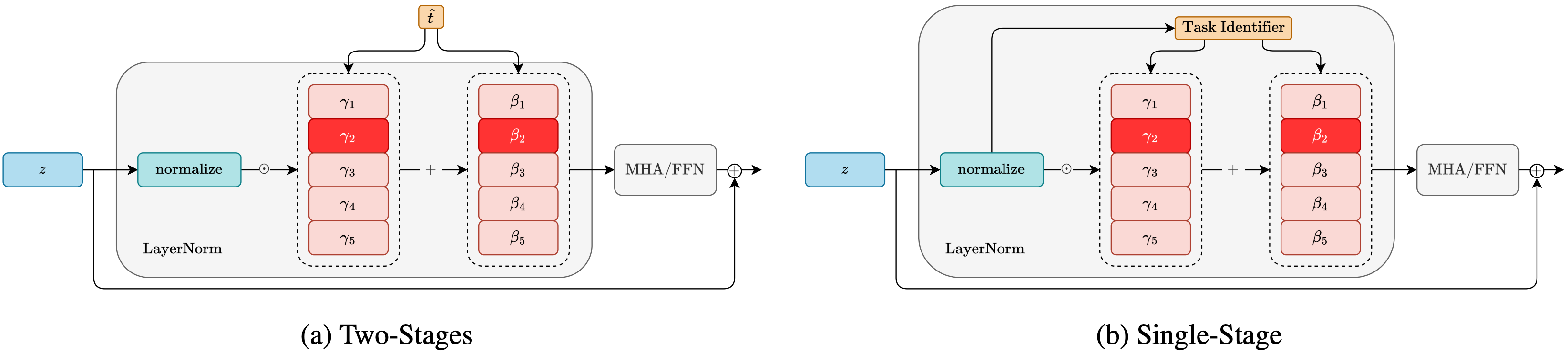
On the Effectiveness of LayerNorm Tuning for Continual Learning in Vision Transformers
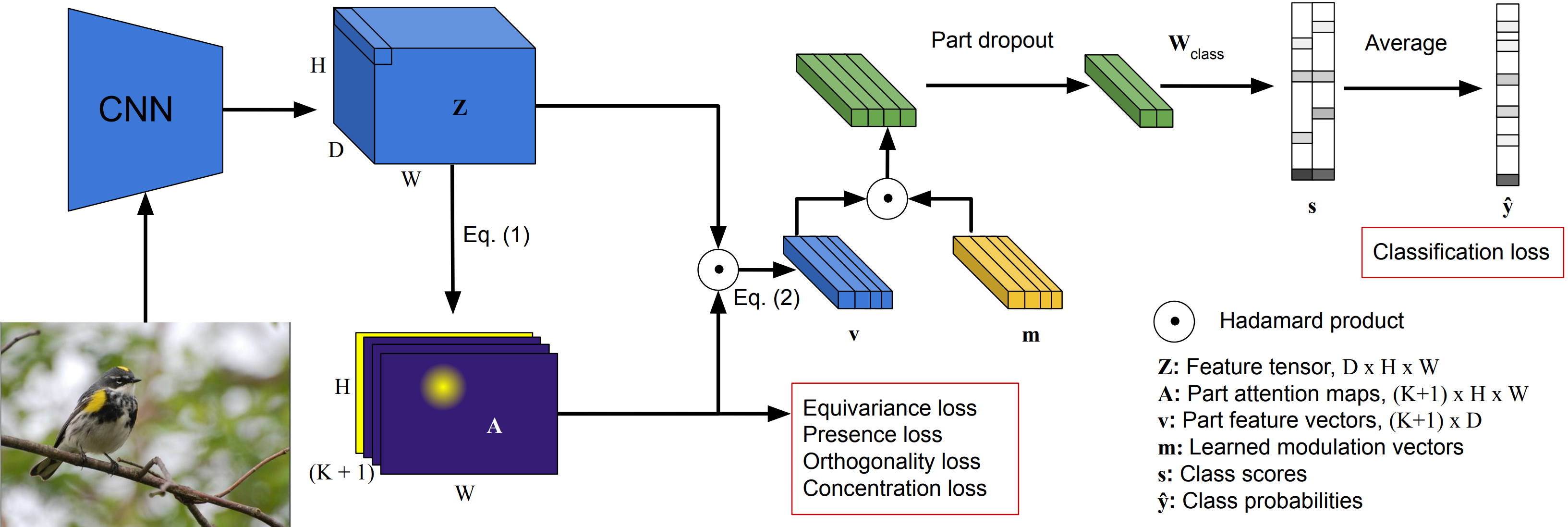
PDiscoNet: Semantically consistent part discovery for fine-grained recognition
Robert van der Klis, Stephan Alaniz, Massimiliano Mancini, Cassio Dantas, Dino Ienco, Diego Marcos
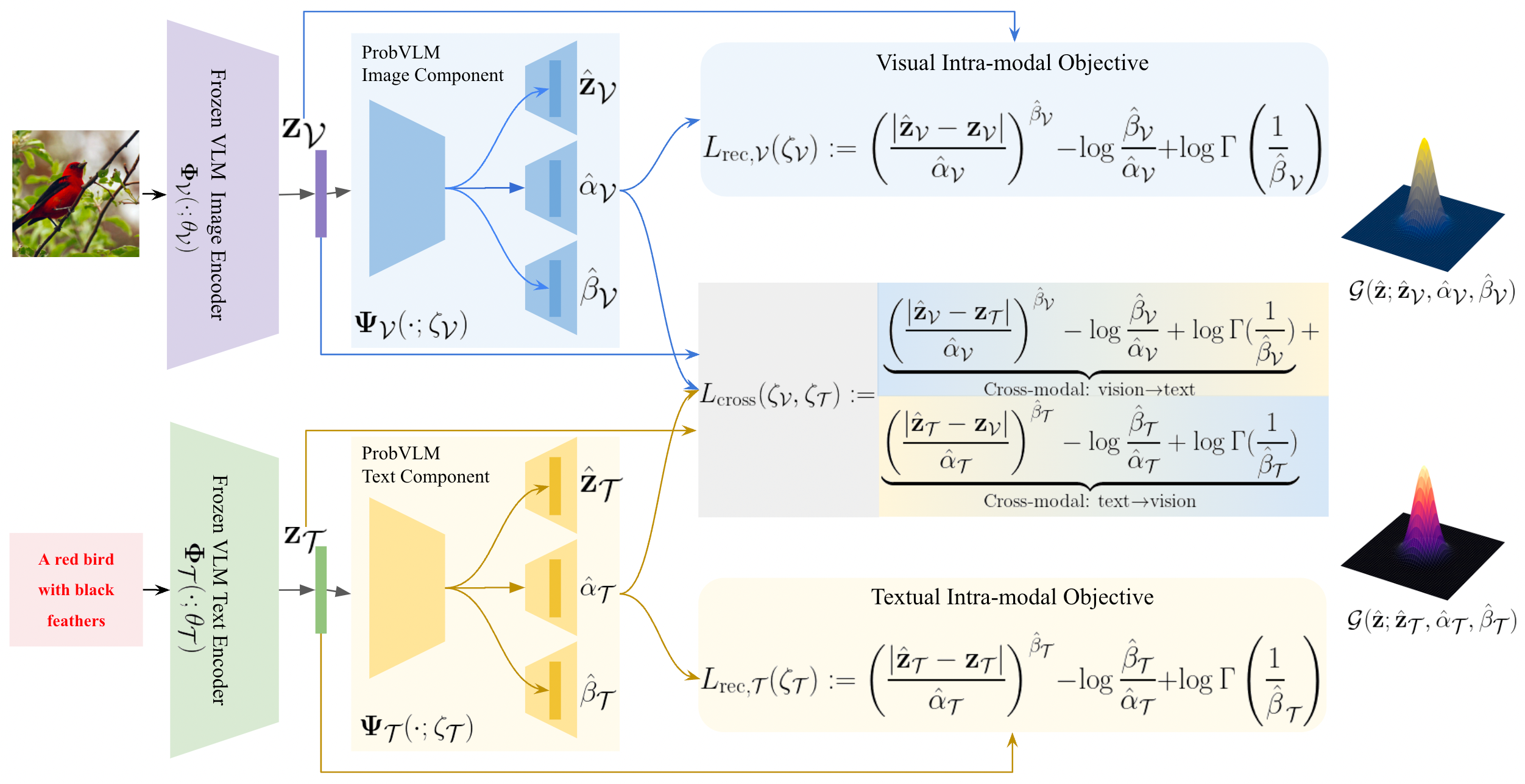
ProbVLM: Probabilistic Adapter for Frozen Vison-Language Models
Uddeshya Upadhyay, Shyamgopal Karthik, Massimiliano Mancini
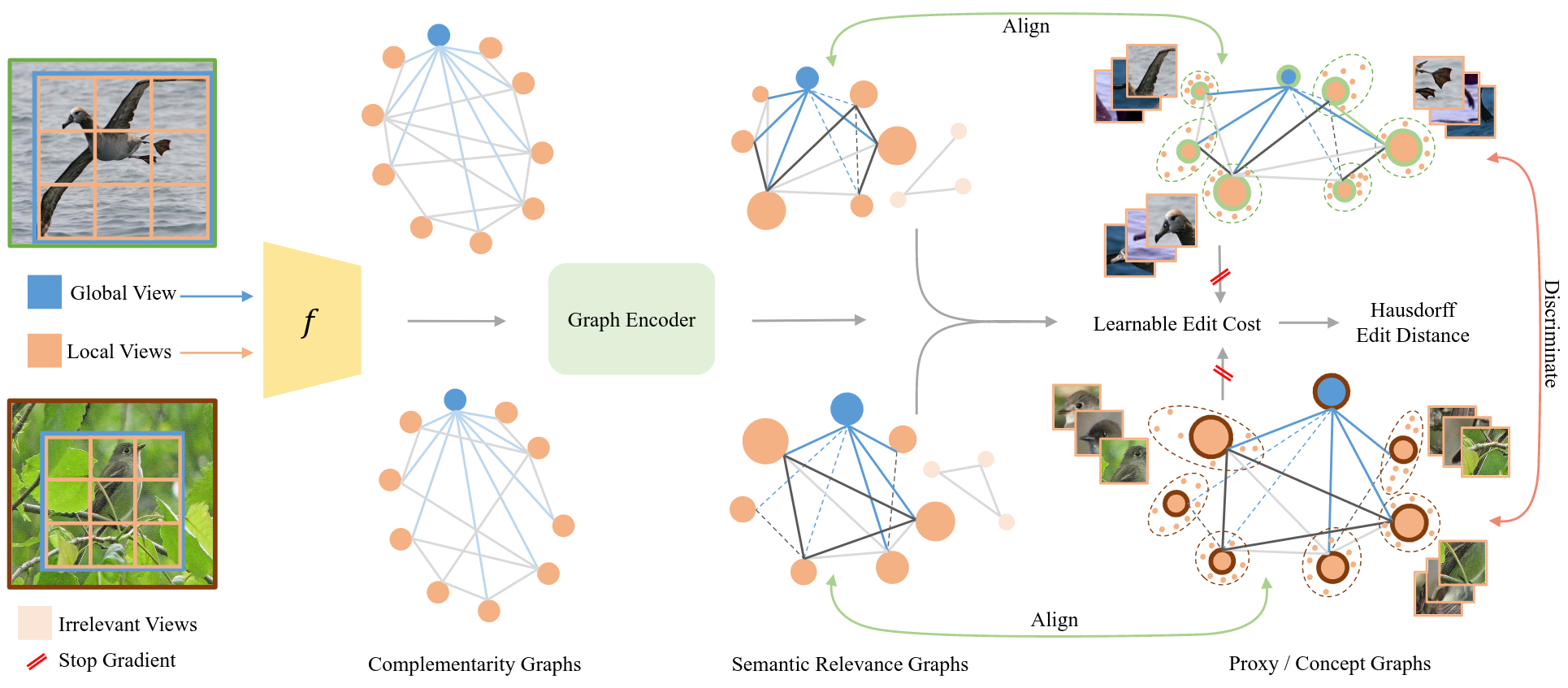
Transitivity Recovering Decompositions: Interpretable and Robust Fine-Grained Relationships
Abhra Chaudhuri, Massimiliano Mancini, Anjan Dutta