About
Elisa Ricci is a Full Professor in the Department of Information Engineering and Computer Science (DISI) at the University of Trento and a Senior Researcher at Fondazione Bruno Kessler (FBK). She is the scientific manager of the Joint Laboratory on Vision and Learning between FBK and DISI. Her research interests are mainly in the areas of computer vision, robotics, machine learning, and human behaviour analysis.
Research Interests
Computer Vision
Papers (73)
2026
From Weights to Concepts: Data-Free Interpretability of CLIP via Singular Vector Decomposition
Francesco Gentile, Nicola Dall'Asen, Francesco Tonini, Massimiliano Mancini, Lorenzo Vaquero, Elisa Ricci

How to Take a Memorable Picture? Empowering Users with Actionable Feedback
Specificity-aware reinforcement learning for fine-grained open-world classification
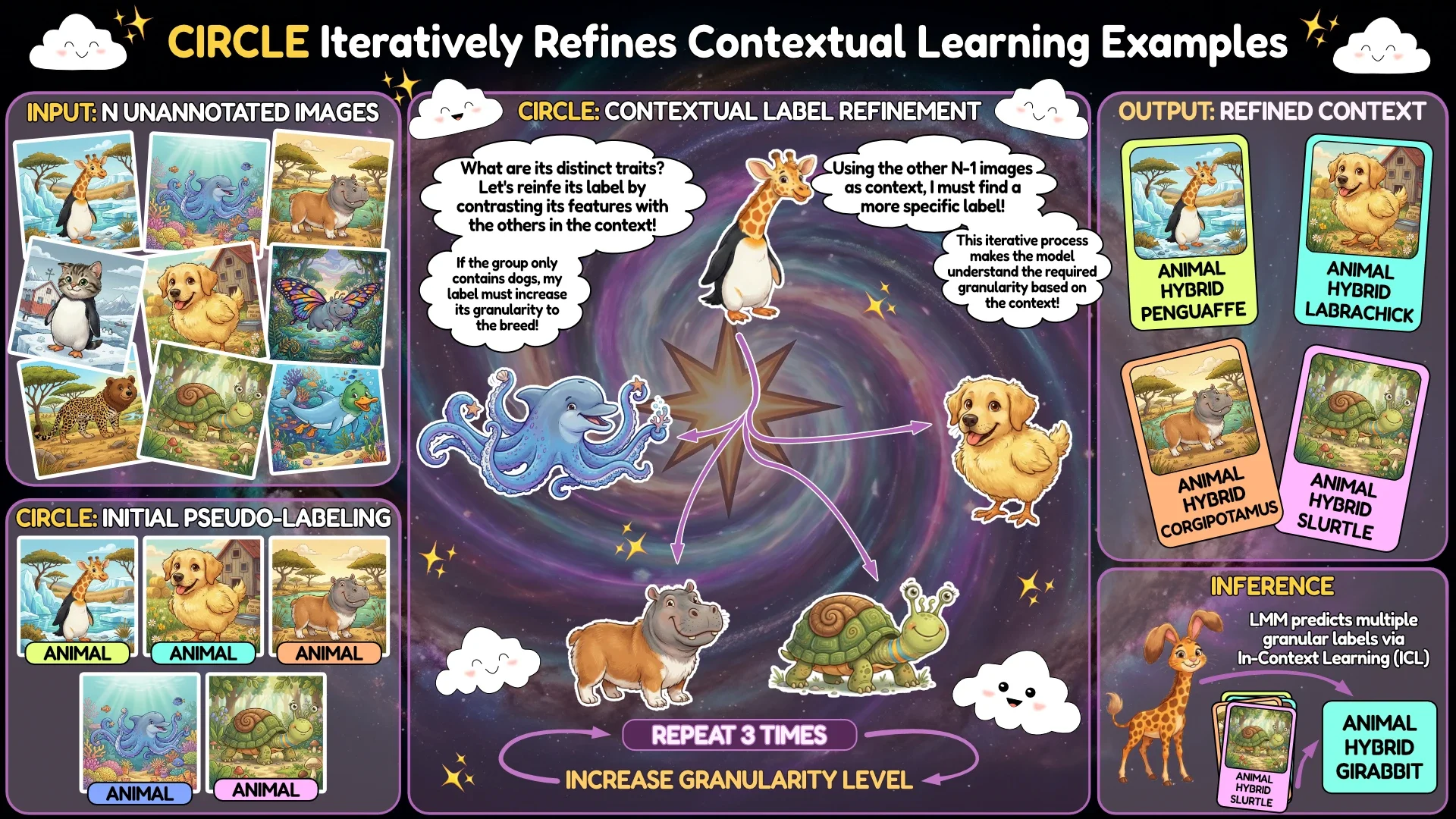
Large Multimodal Models as General In-Context Classifiers
Organizing Unstructured Image Collections using Natural Language
SEM: Sparse Embedding Modulation for Post-Hoc Debiasing of Vision-Language Models
Quentin Guimard, Federico Bartsch, Simone Caldarella, Rahaf Aljundi, Elisa Ricci, Massimiliano Mancini
2025

ConViS-Bench: Estimating Video Similarity Through Semantic Concepts
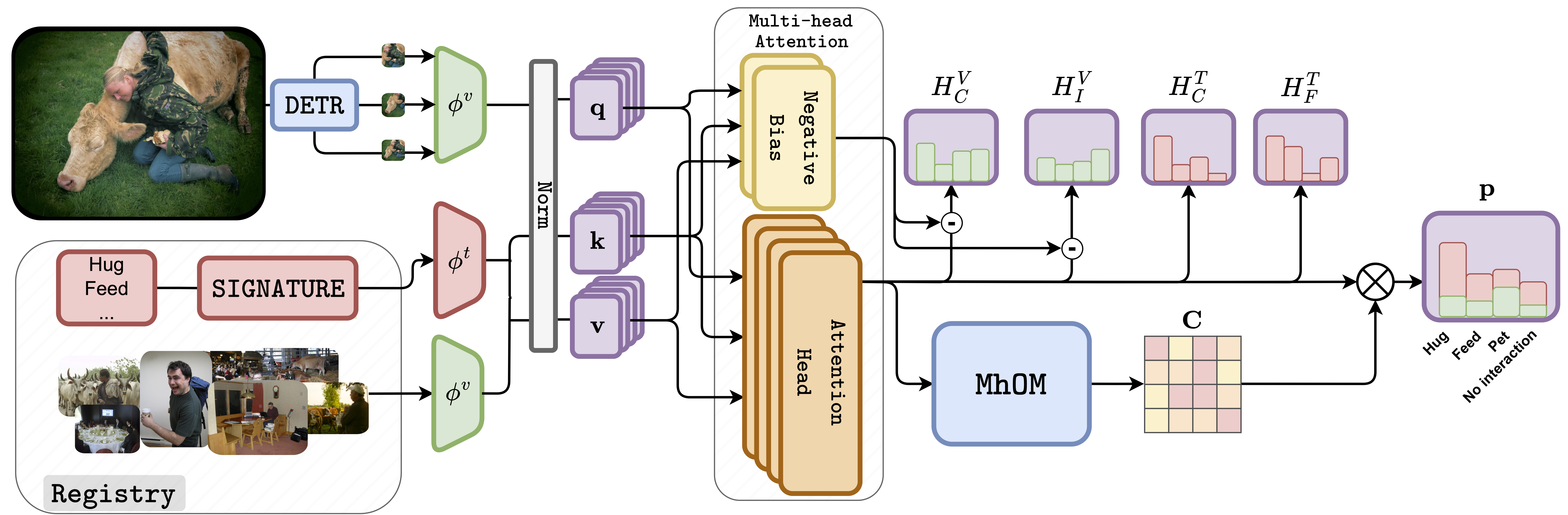
Dynamic Scoring with Enhanced Semantics for Training-Free Human-Object Interaction Detection

FedMVP: Federated Multimodal Visual Prompt Tuning for Vision-Language Models
Mainak Singha, Subhankar Roy, Sarthak Mehrotra, Ankit Jha, Moloud Abdar, Biplap Banerjee, Elisa Ricci
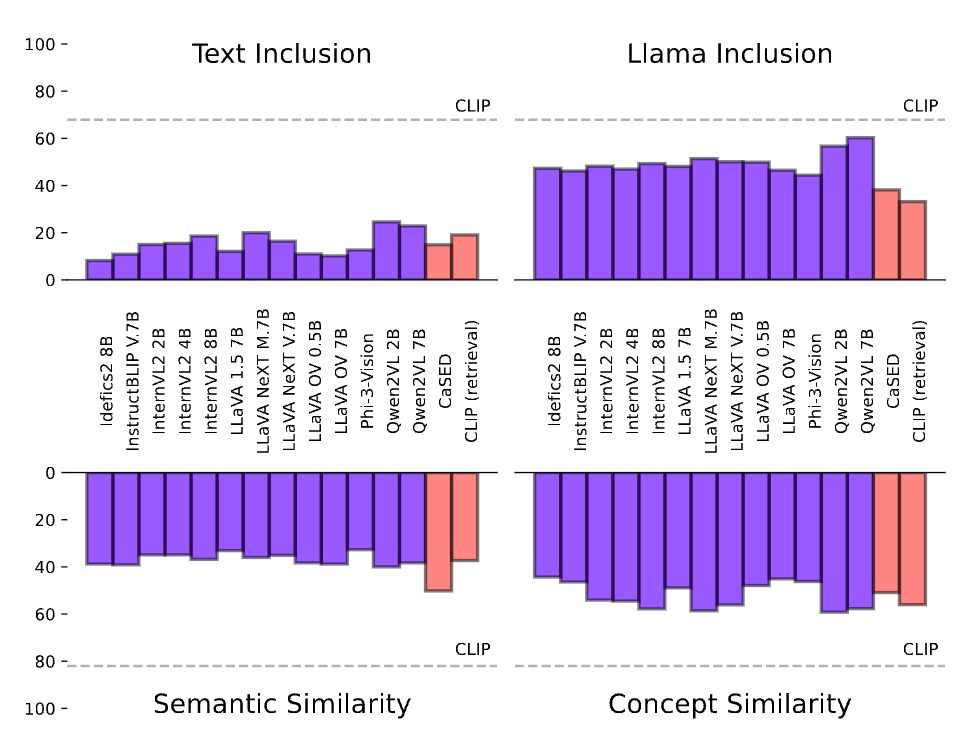
On Large Multimodal Models as Open-World Image Classifiers
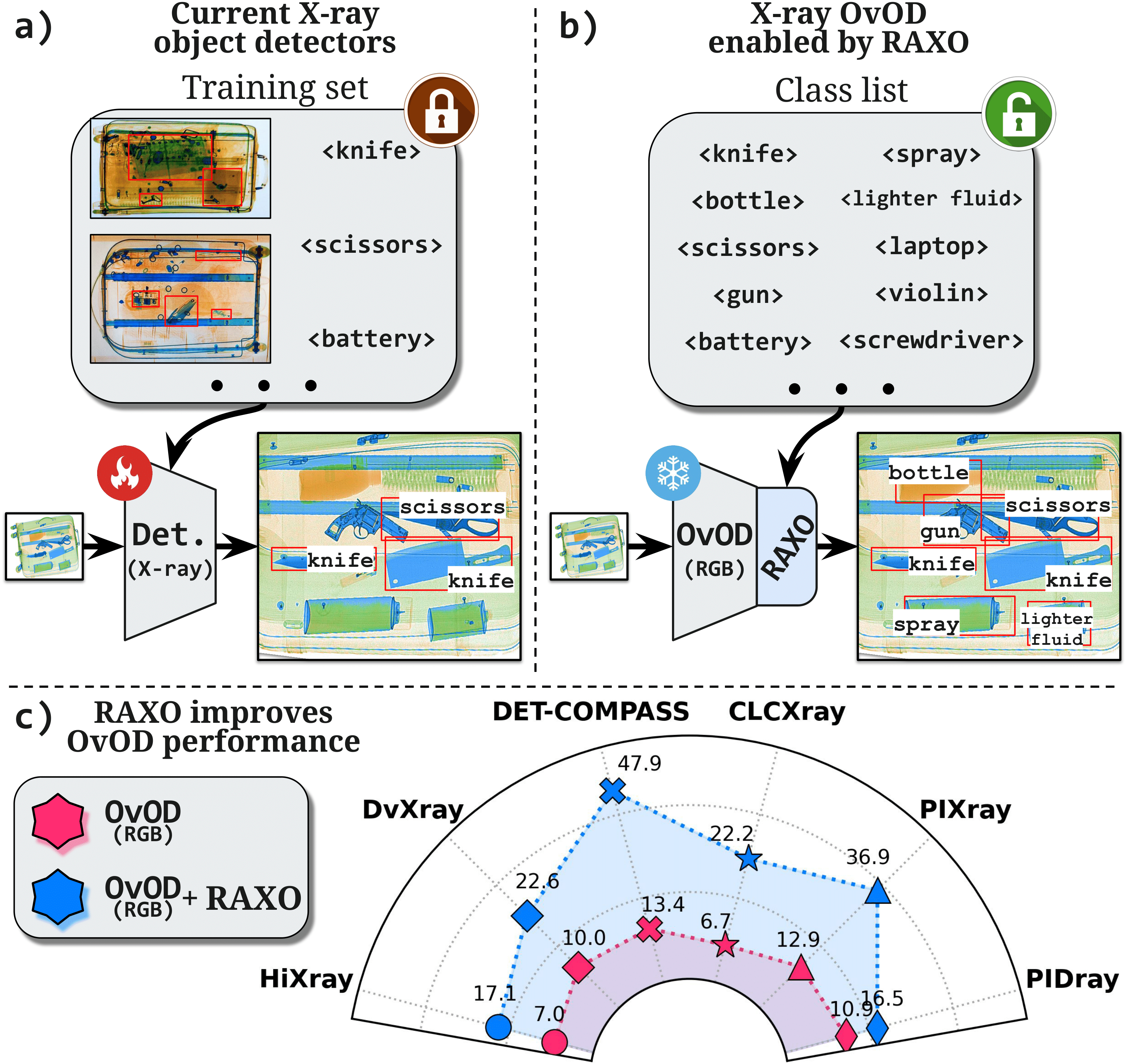
Superpowering Open-Vocabulary Object Detectors for X-ray Vision
Pablo García Fernández, Lorenzo Vaquero, Mingxuan Liu, Feng Xue, Daniel Cores, Nicu Sebe, Manuel Mucientes, Elisa Ricci
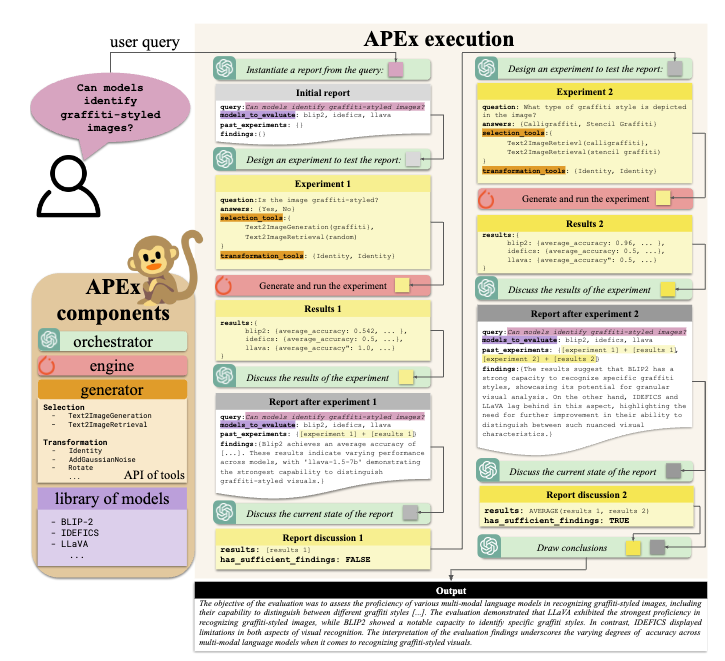
Automatic benchmarking of large multimodal models via iterative experiment programming
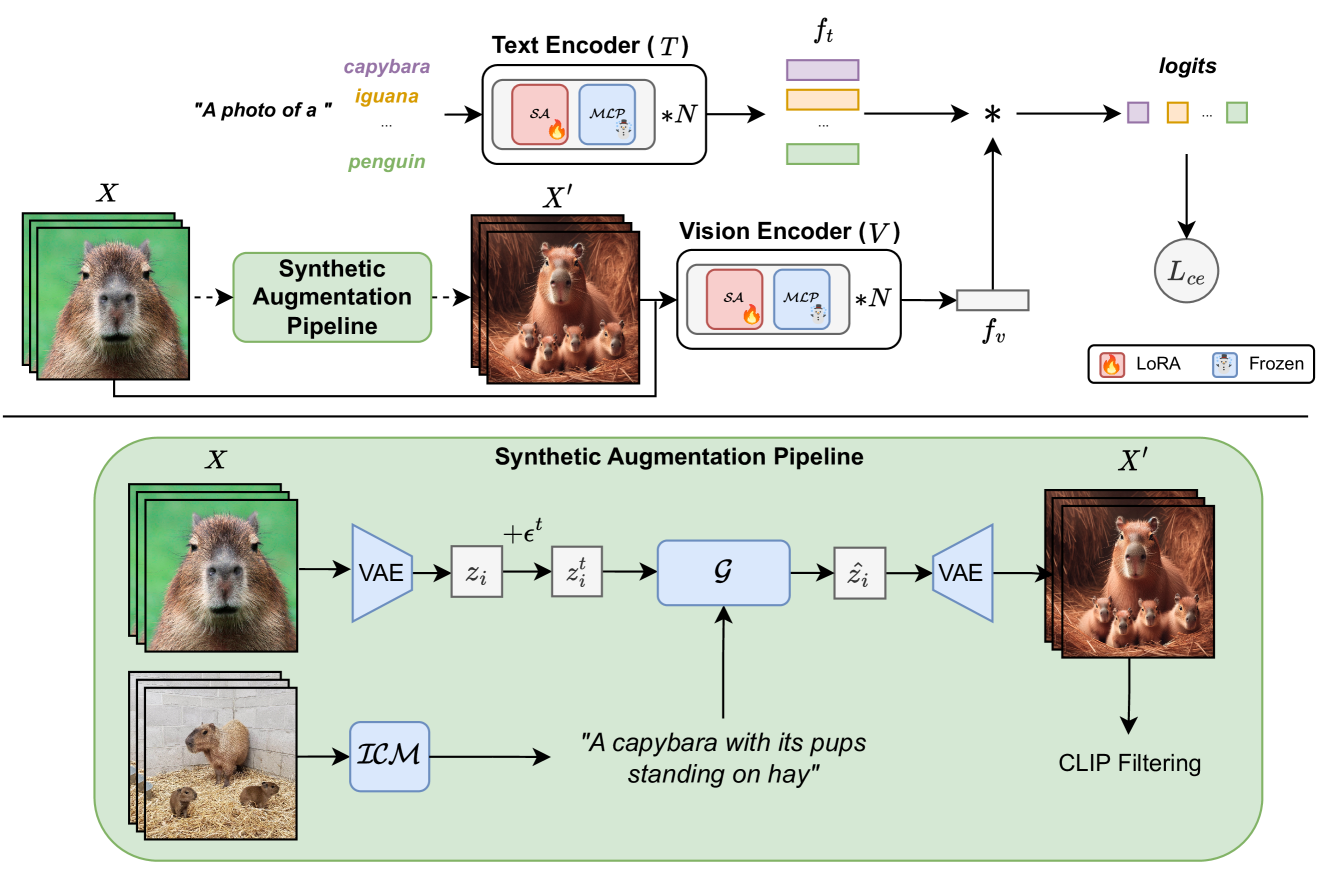
Diversified in-domain synthesis with efficient fine-tuning for few-shot classification
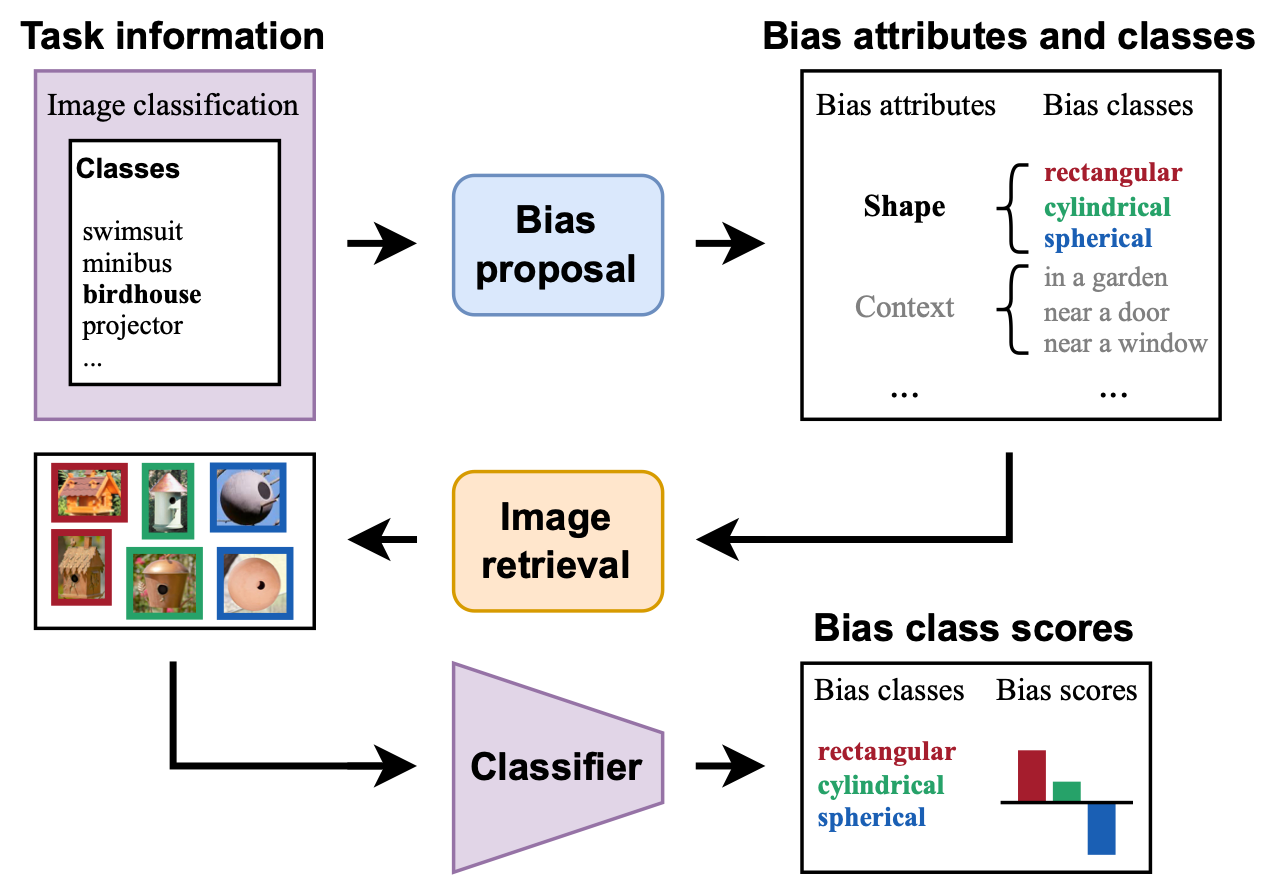
Classifier-to-Bias: Toward Unsupervised Automatic Bias Detection for Visual Classifiers

Highlight
Compositional Caching for Training-free Open-vocabulary Attribute Detection
Highlight
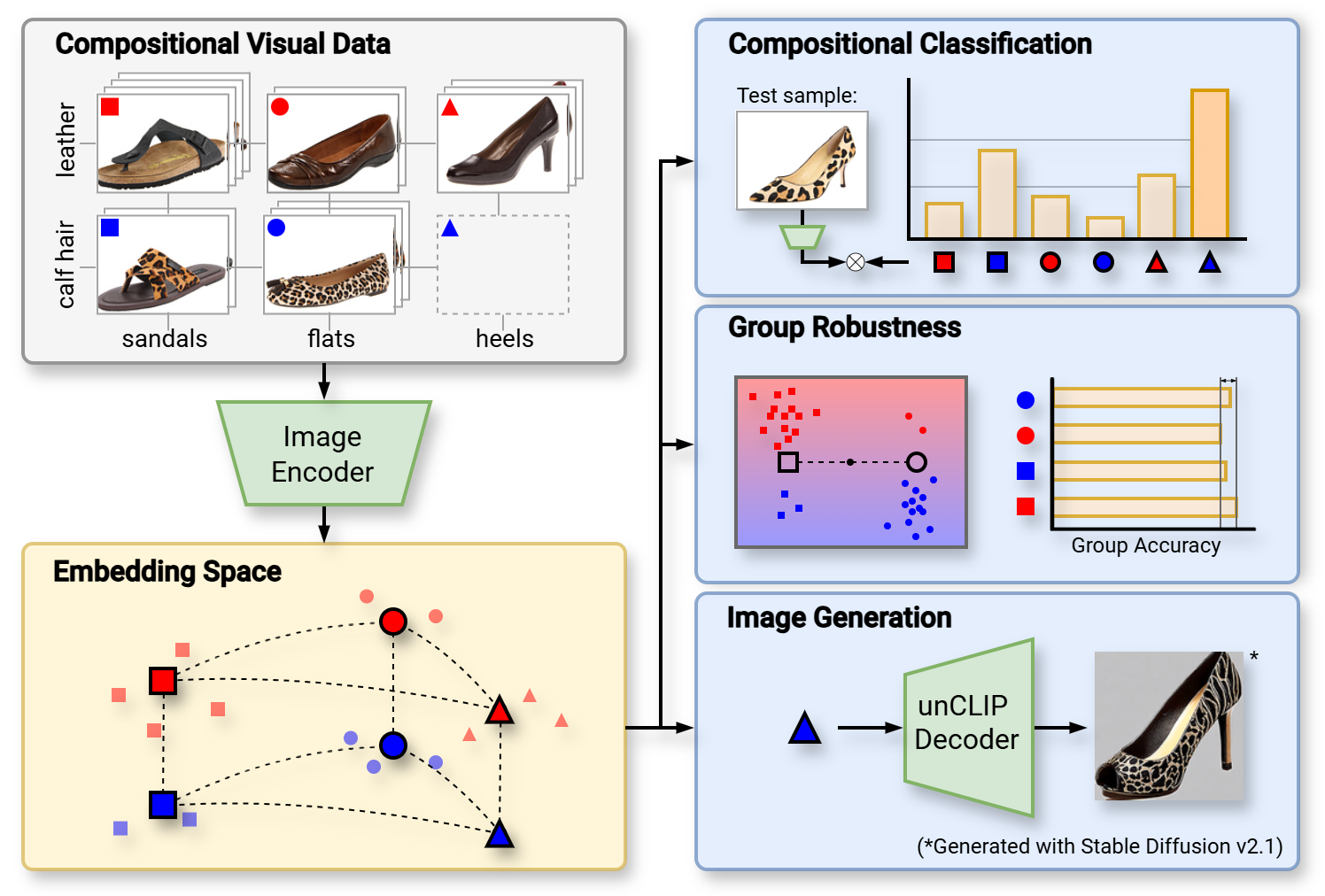
Not Only Text: Exploring Compositionality of Visual Representations in Vision-Language Models
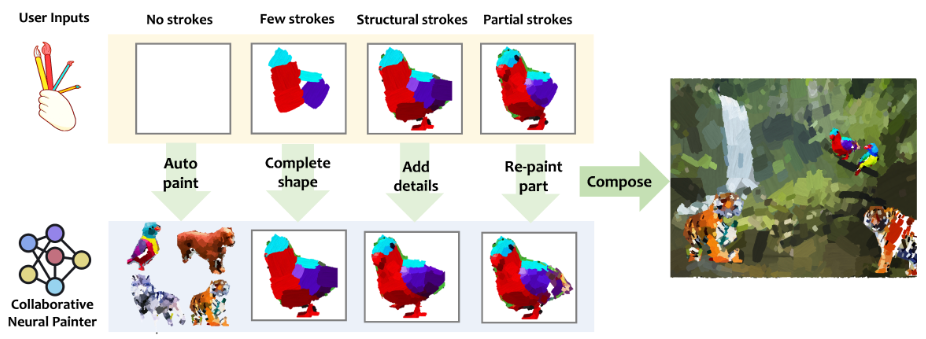
Collaborative Neural Painting

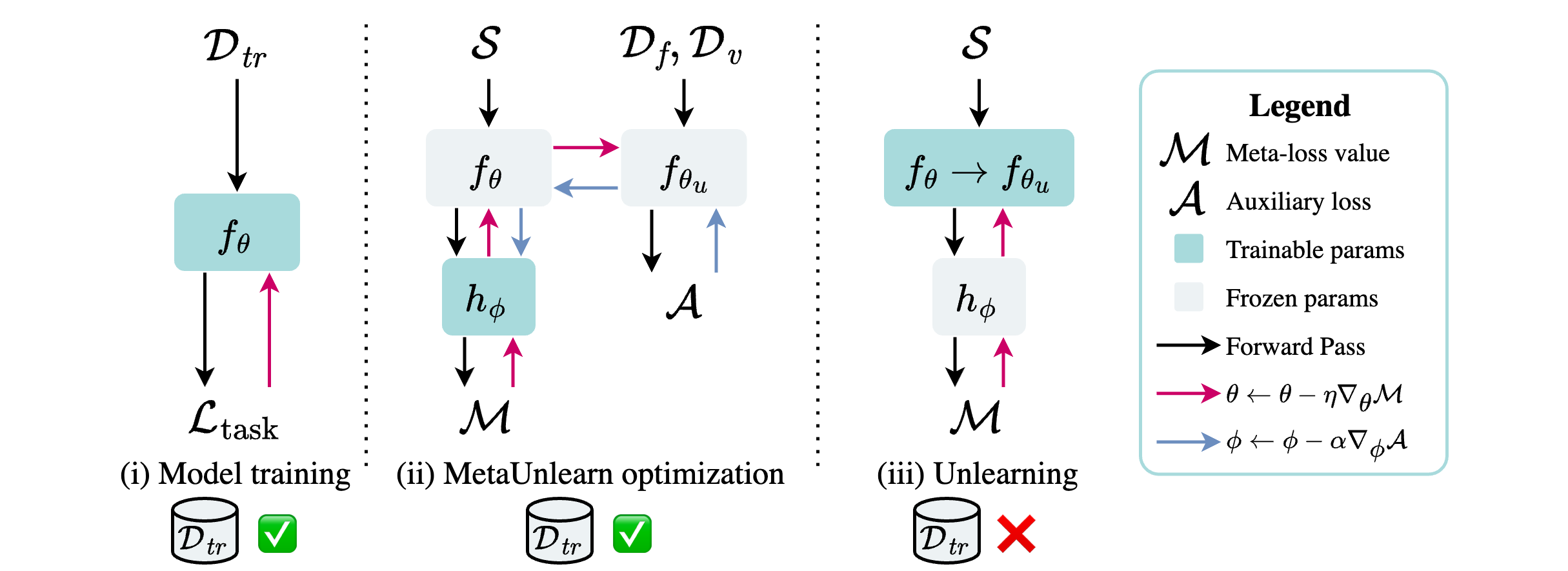
Group-robust Machine Unlearning
Unlearning Personal Data from a Single Image
2024
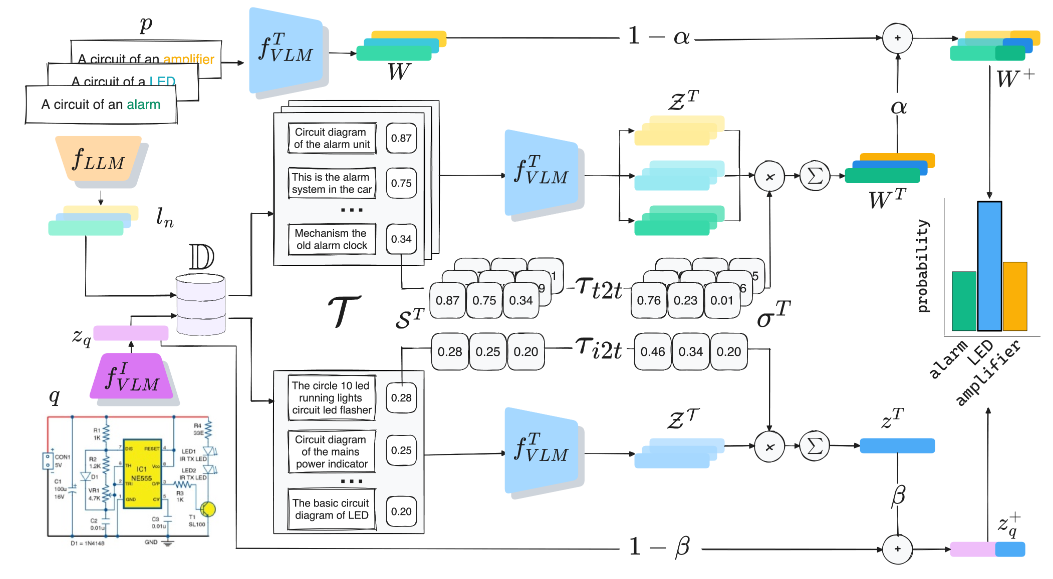
Retrieval-enriched zero-shot image classification in low-resource domains
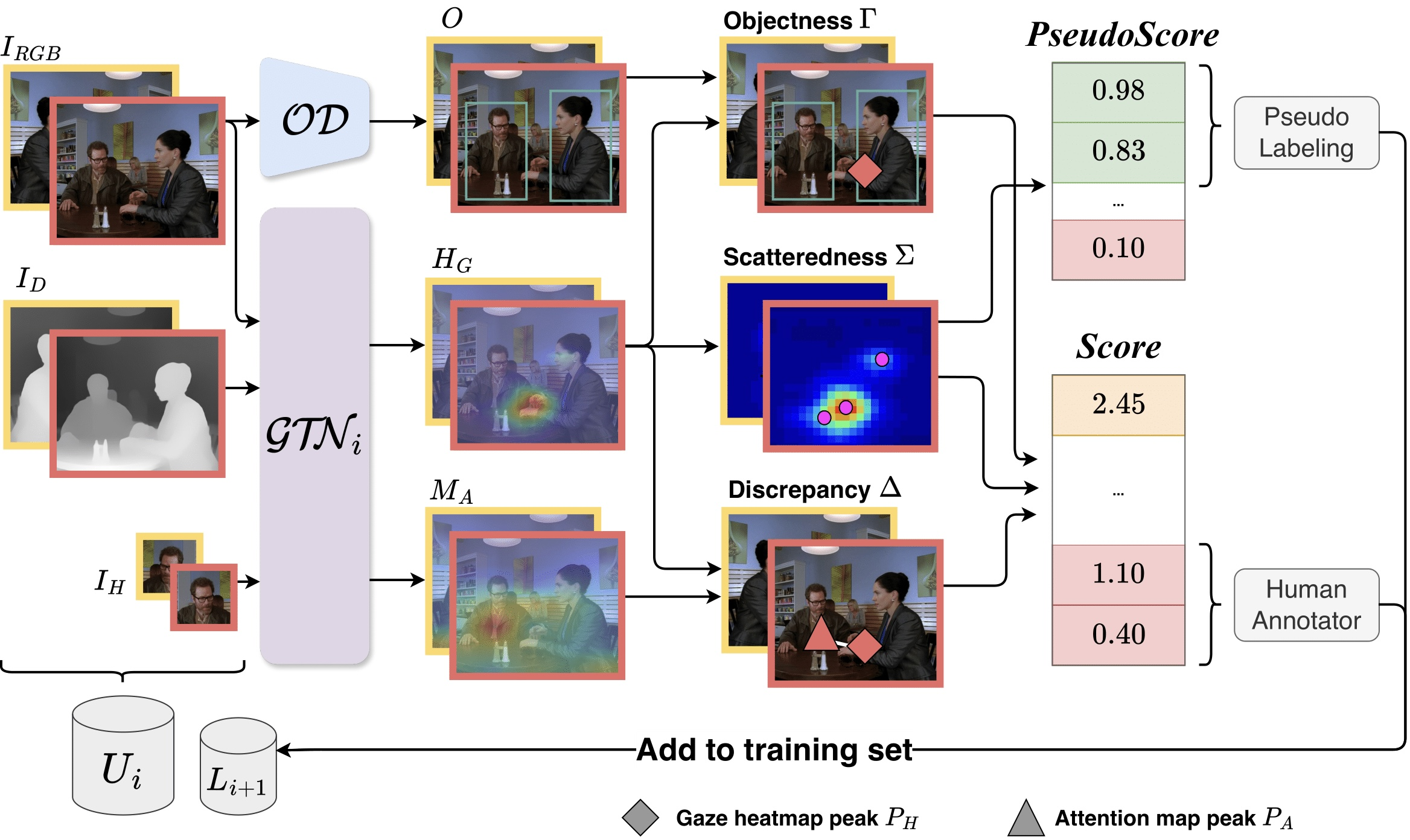
AL-GTD: Deep Active Learning for Gaze Target Detection
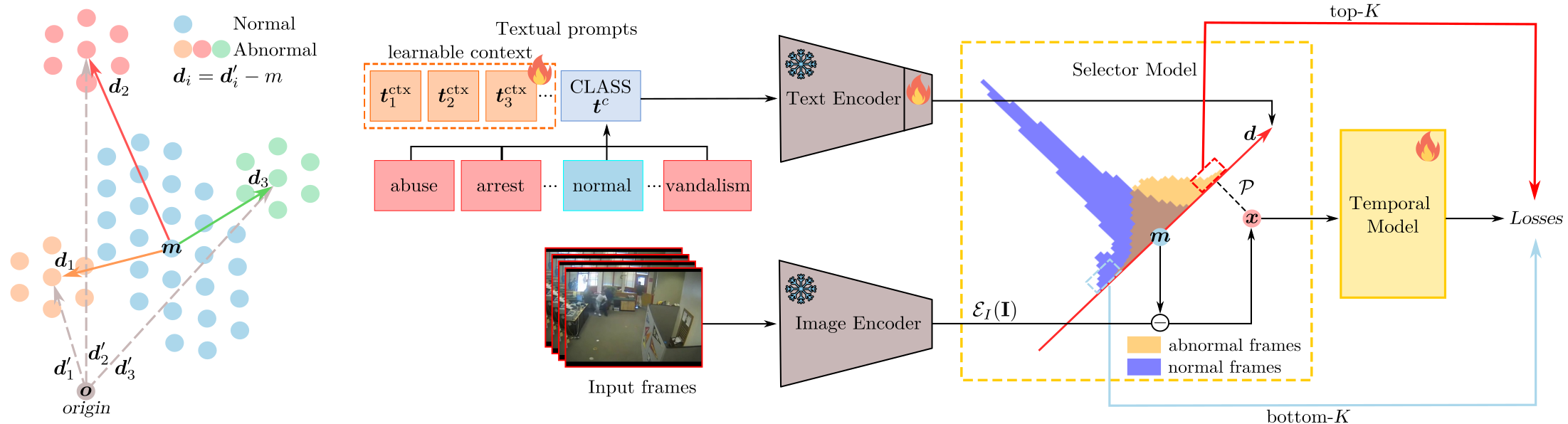
Delving into CLIP latent space for Video Anomaly Recognition
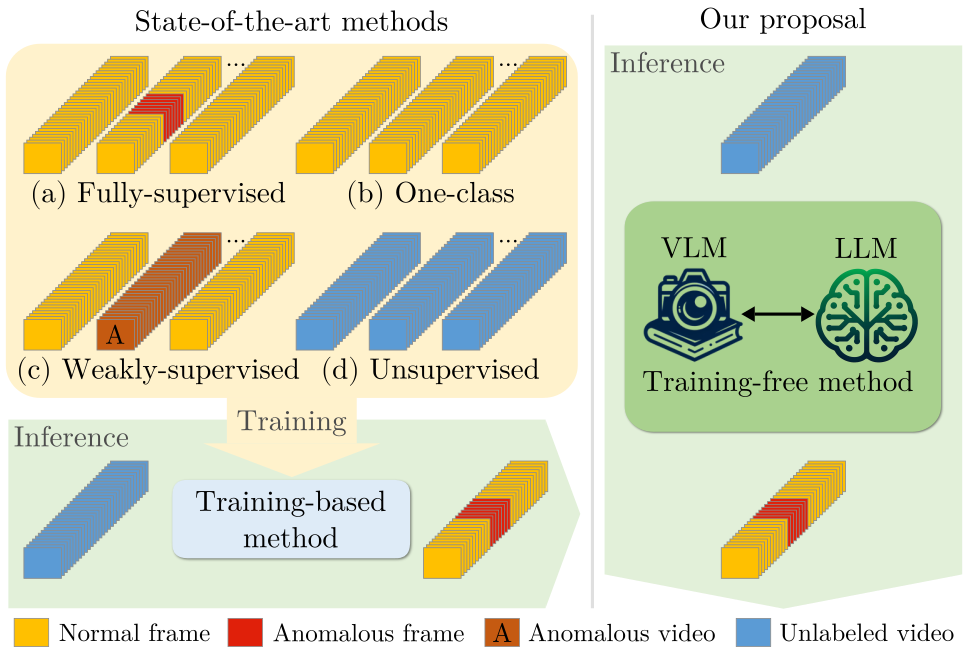
Harnessing Large Language Models for Training-free Video Anomaly Detection
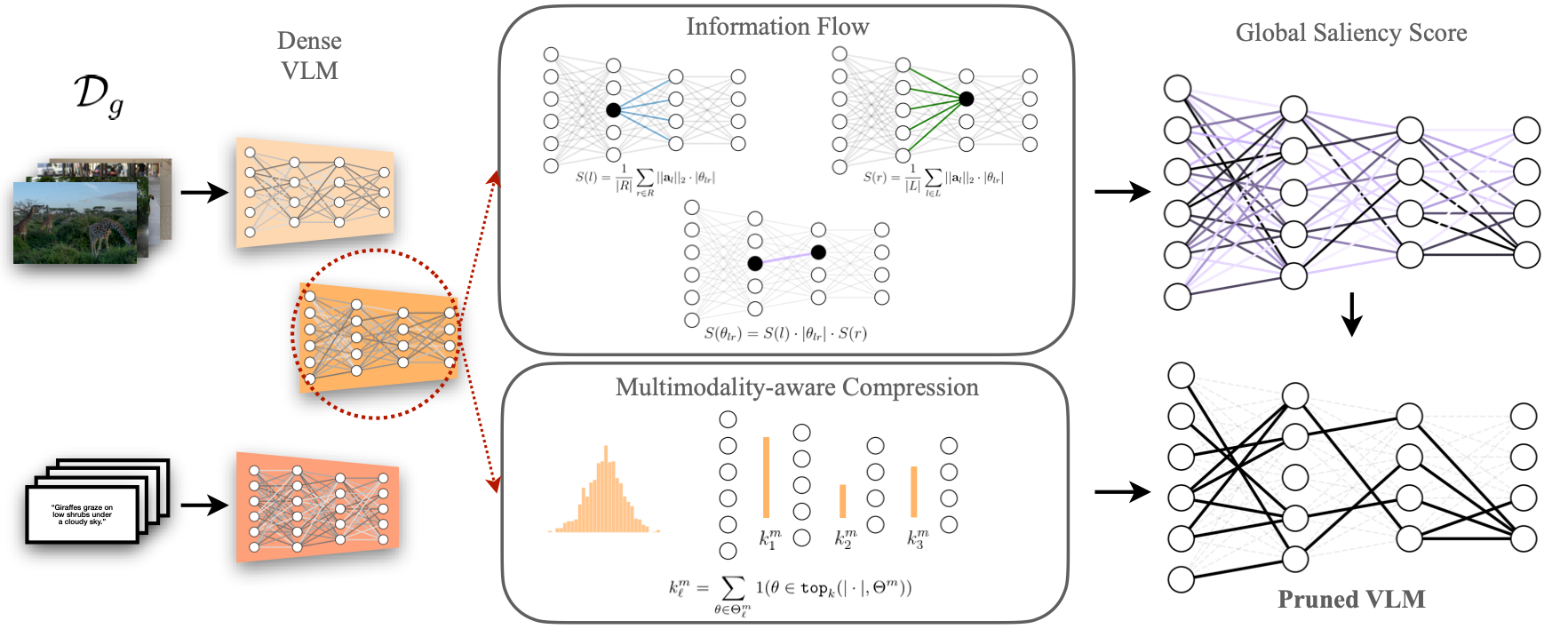
MULTIFLOW: Shifting Towards Task-Agnostic Vision-Language Pruning
Highlight
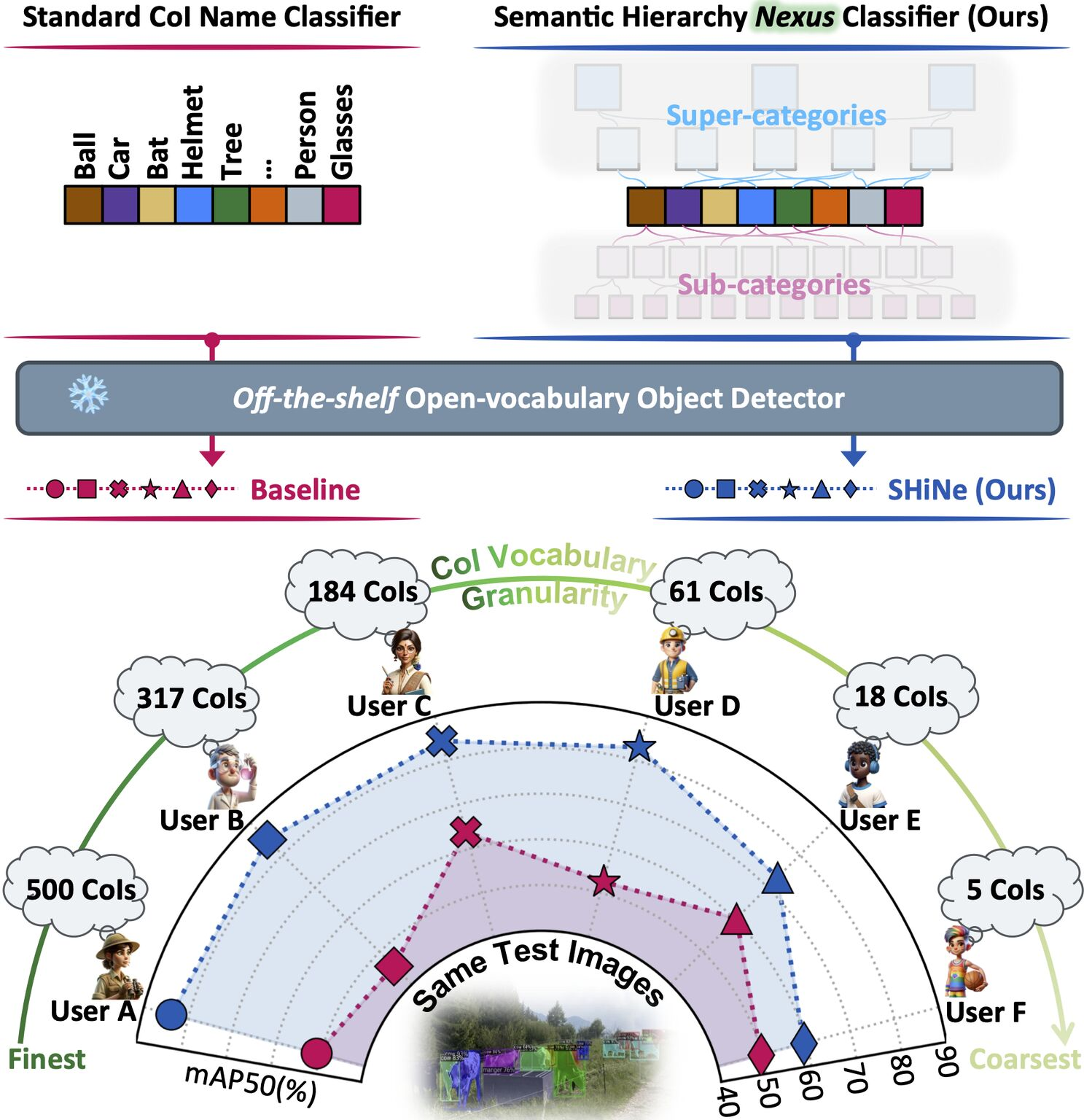
SHiNe: Semantic Hierarchy Nexus for Open-vocabulary Object Detection
Mingxuan Liu, Tyler L. Hayes, Gabriela Csurka, Elisa Ricci, Riccardo Volpi
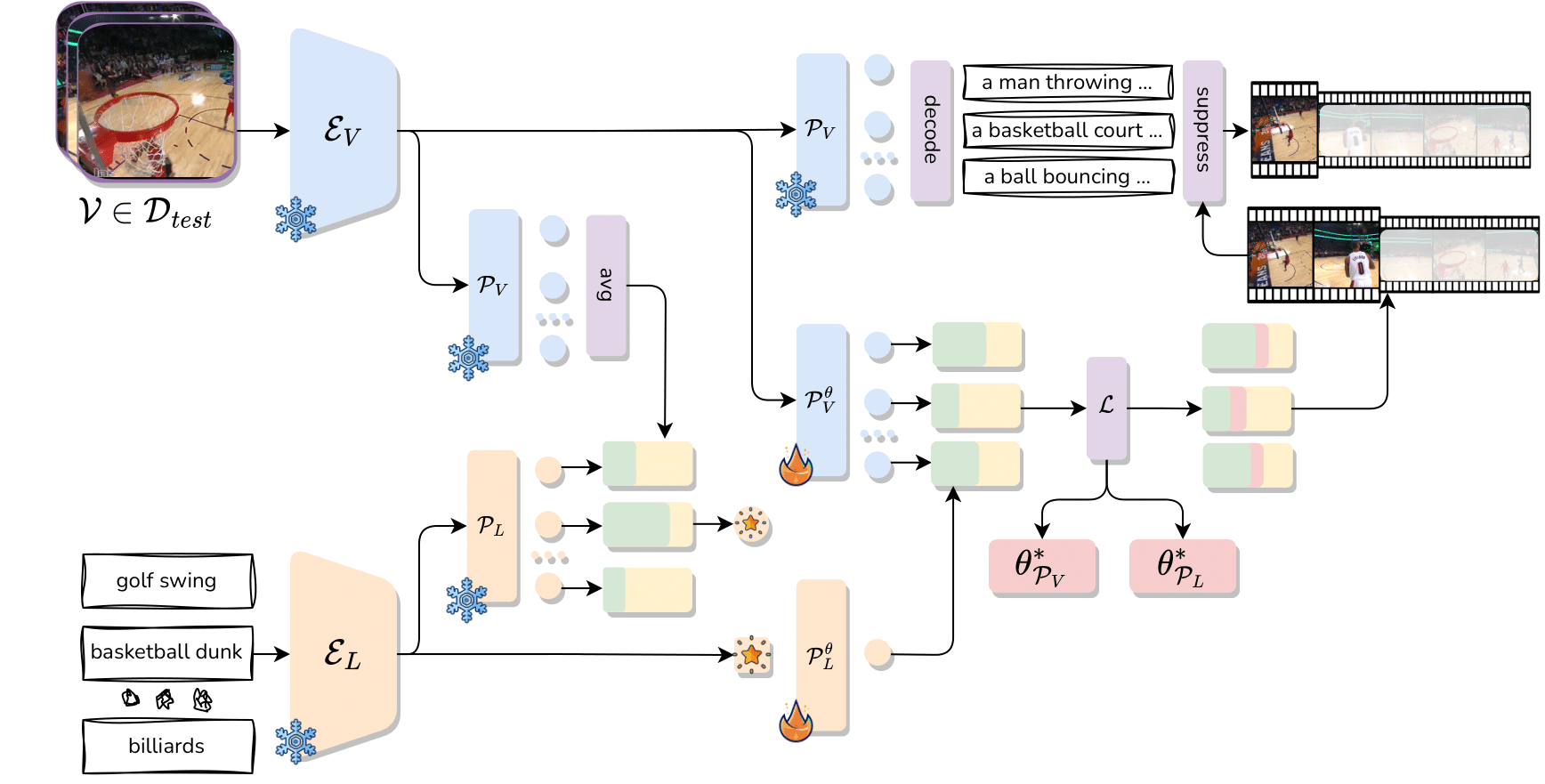
Test-Time Zero-Shot Temporal Action Localization
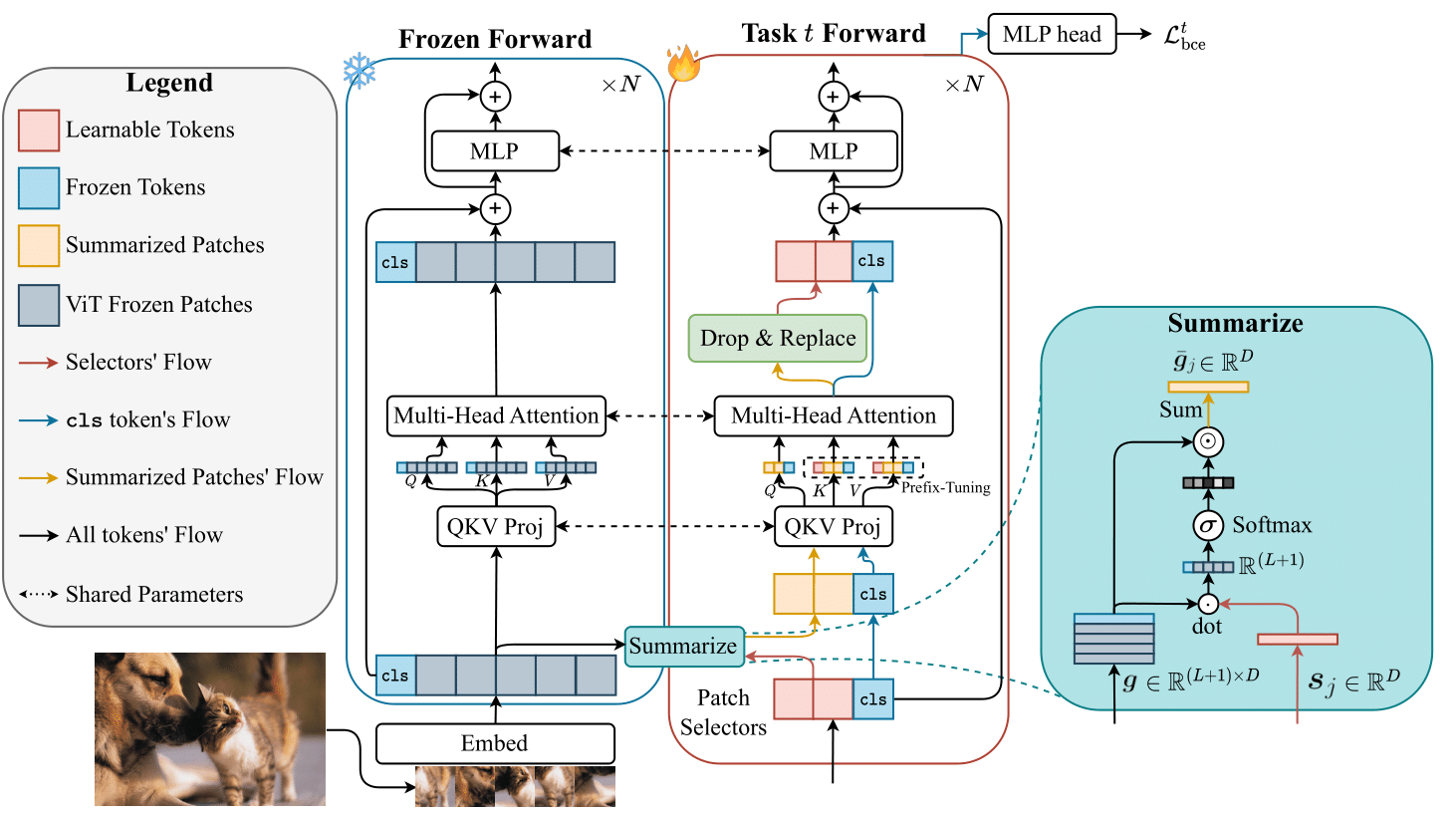
Less is more: Summarizing Patch Tokens for efficient Multi-Label Class-Incremental Learning
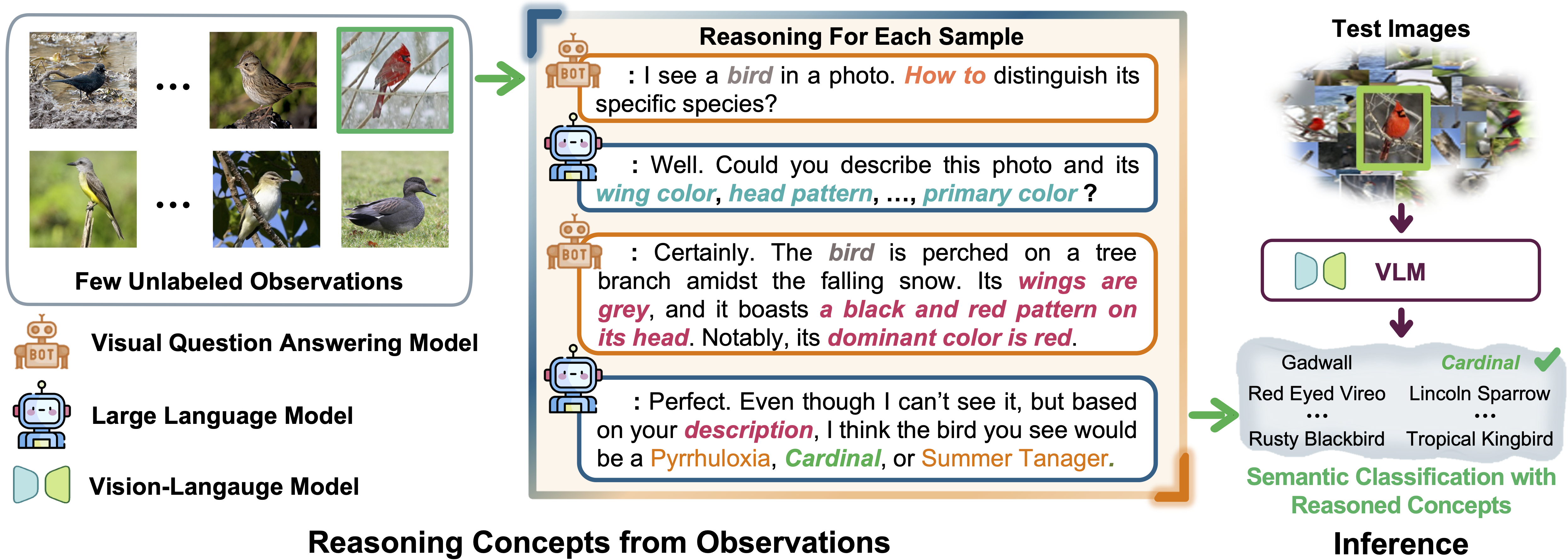
Democratizing Fine-grained Visual Recognition with Large Language Models
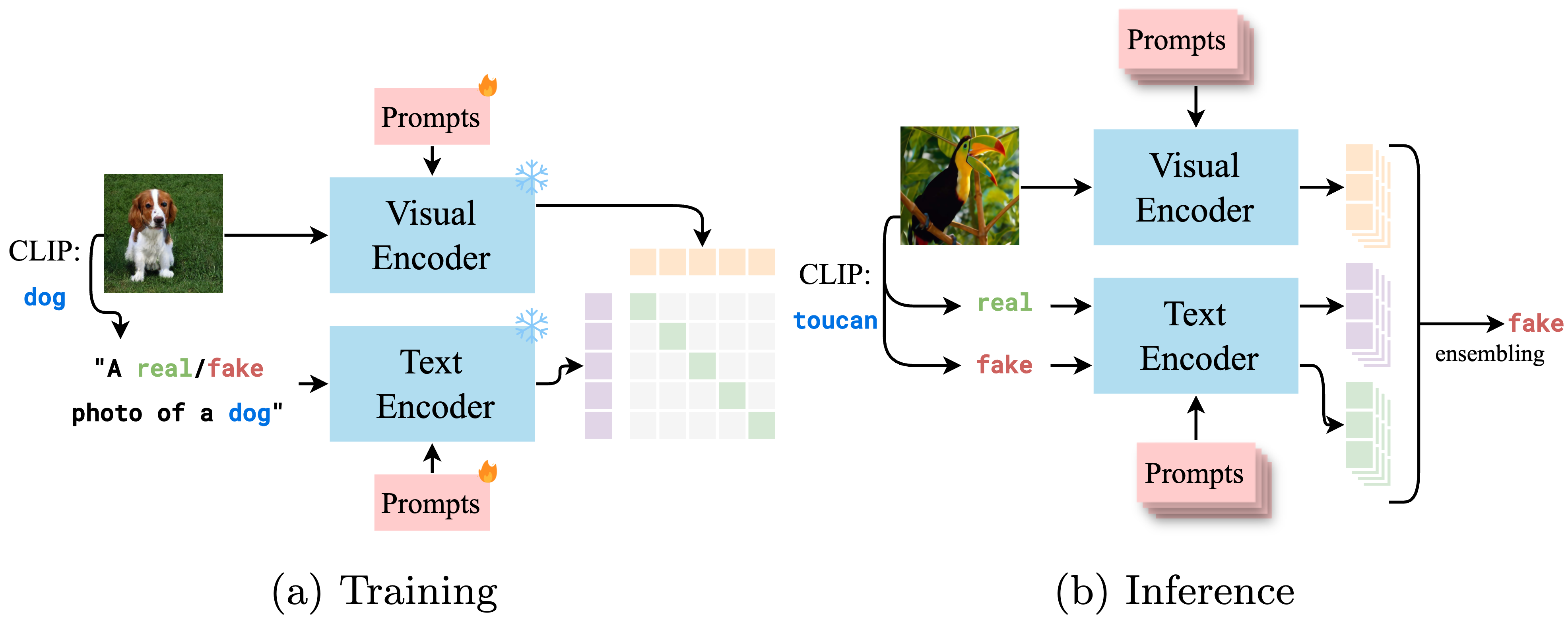
Conditioned Prompt-Optimization for Continual Deepfake Detection
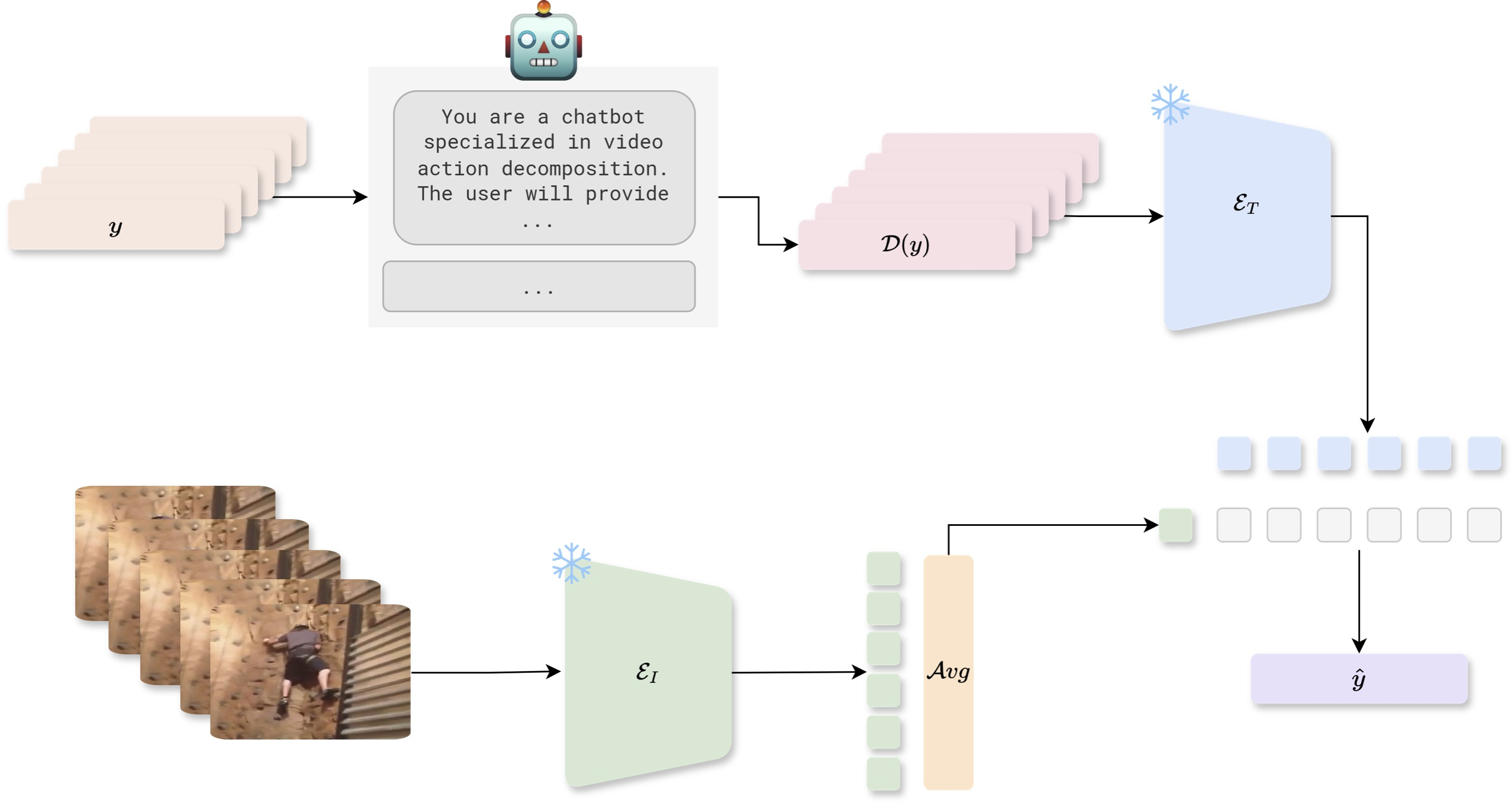
Text-Enhanced Zero-Shot Action Recognition: A training-free approach

Frustratingly Easy Test-Time Adaptation of Vision-Language Models
2023
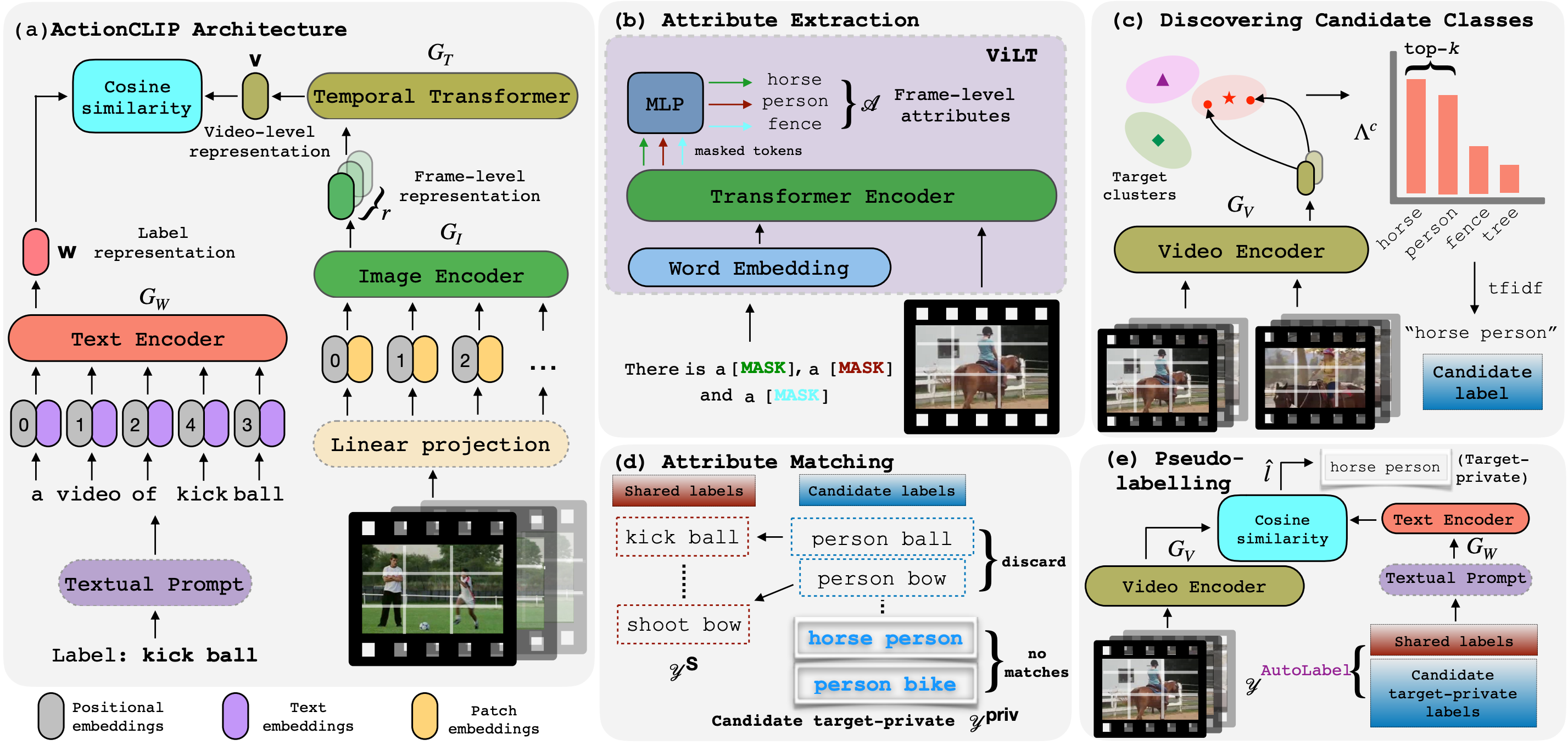
AutoLabel: CLIP-based framework for Open-set Video Domain Adaptation
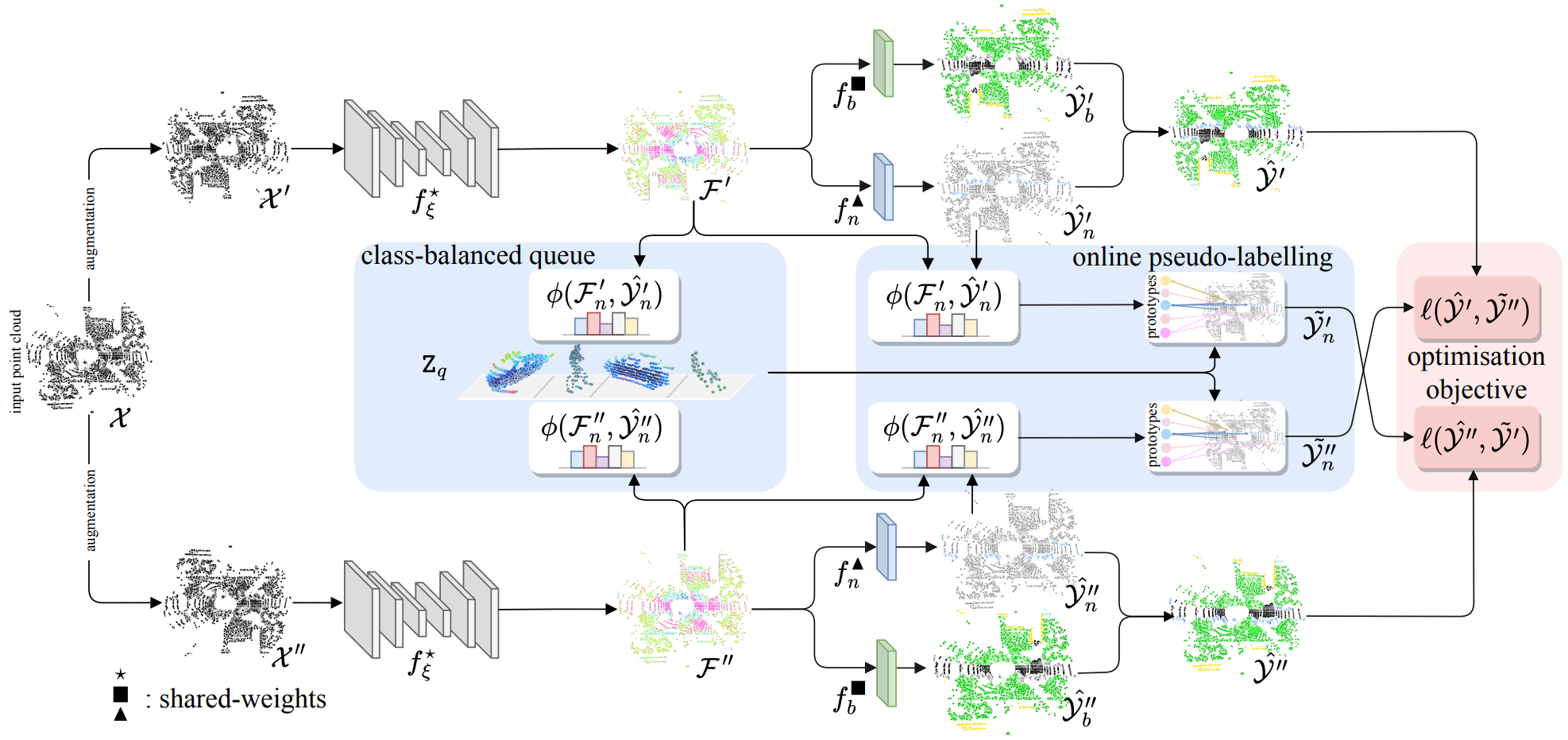
Novel Class Discovery for 3D Point Cloud Semantic Segmentation
Luigi Riz, Cristiano Saltori, Elisa Ricci, Fabio Poiesi
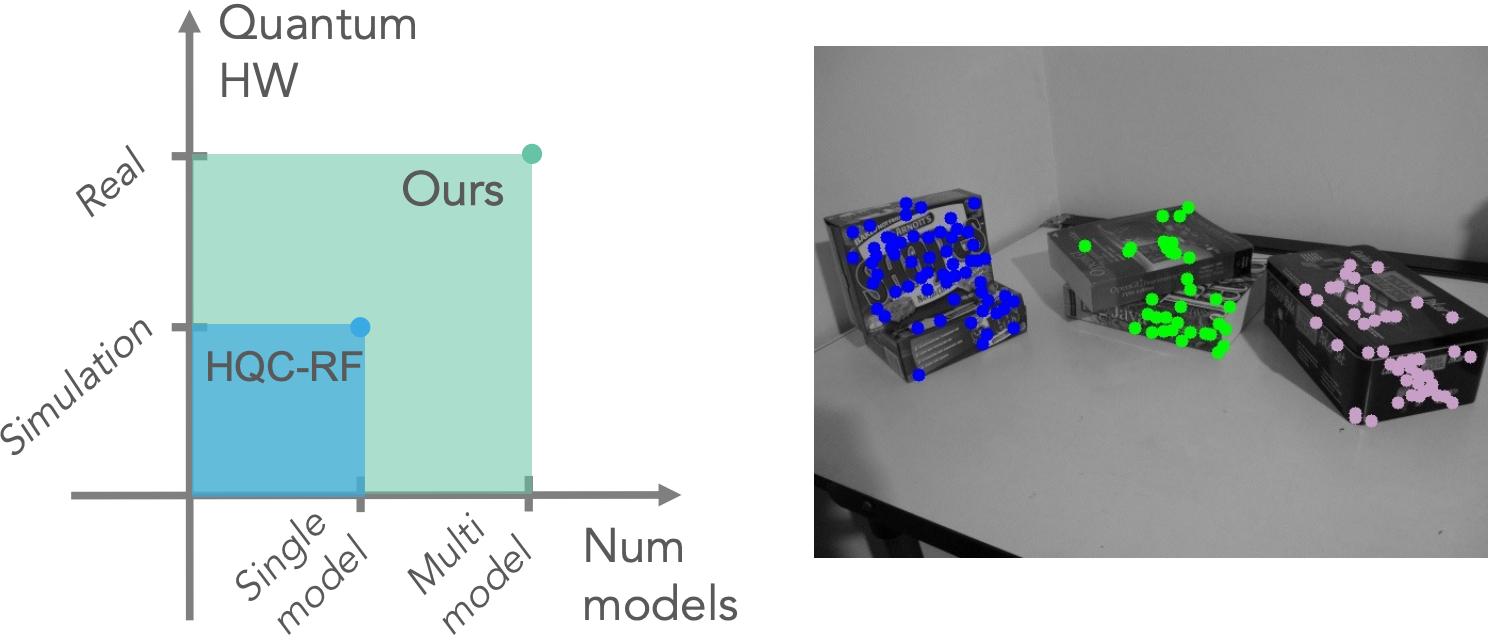
Highlight
Quantum Multi-Model Fitting
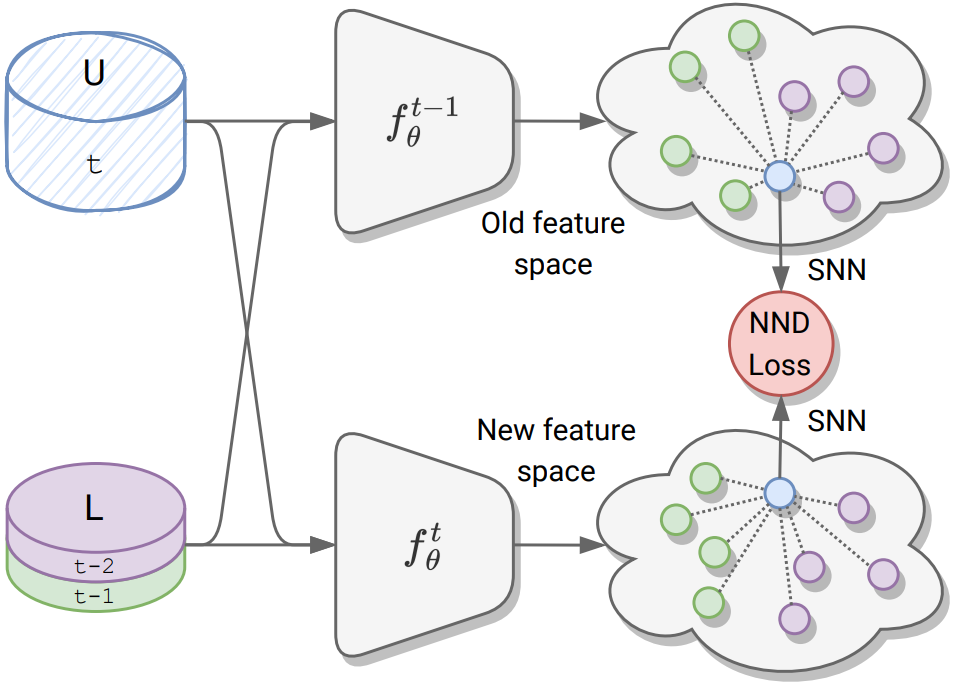
Oral
A soft nearest-neighbor framework for continual semi-supervised learning
Zhiqi Kang, Enrico Fini, Moin Nabi, Elisa Ricci, Karteek Alahari
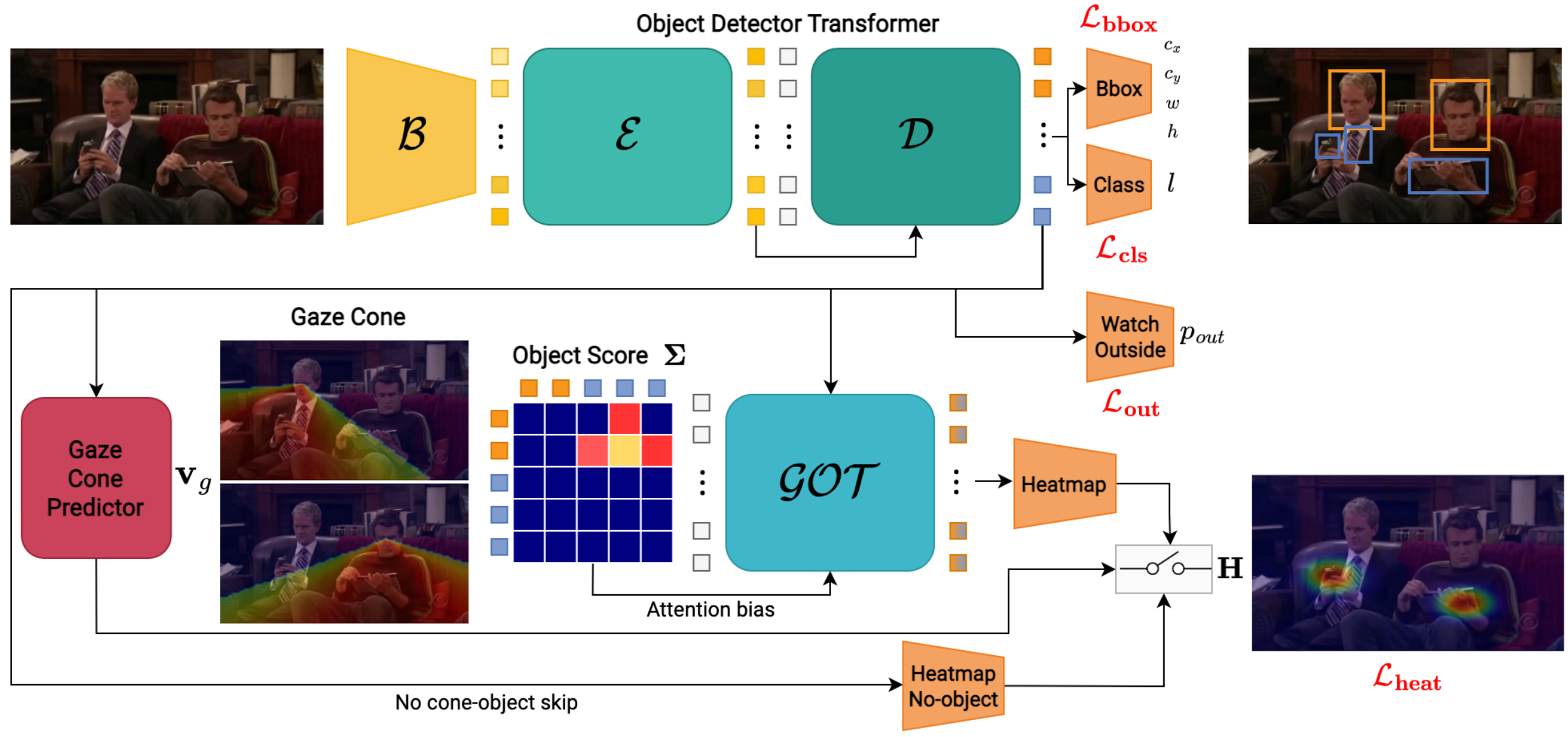
Object-aware Gaze Target Detection
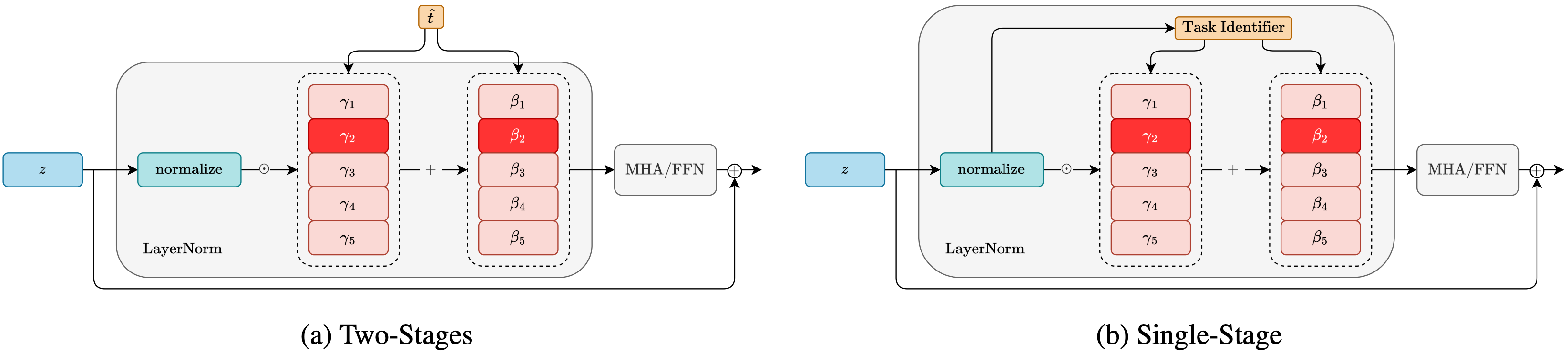
On the Effectiveness of LayerNorm Tuning for Continual Learning in Vision Transformers
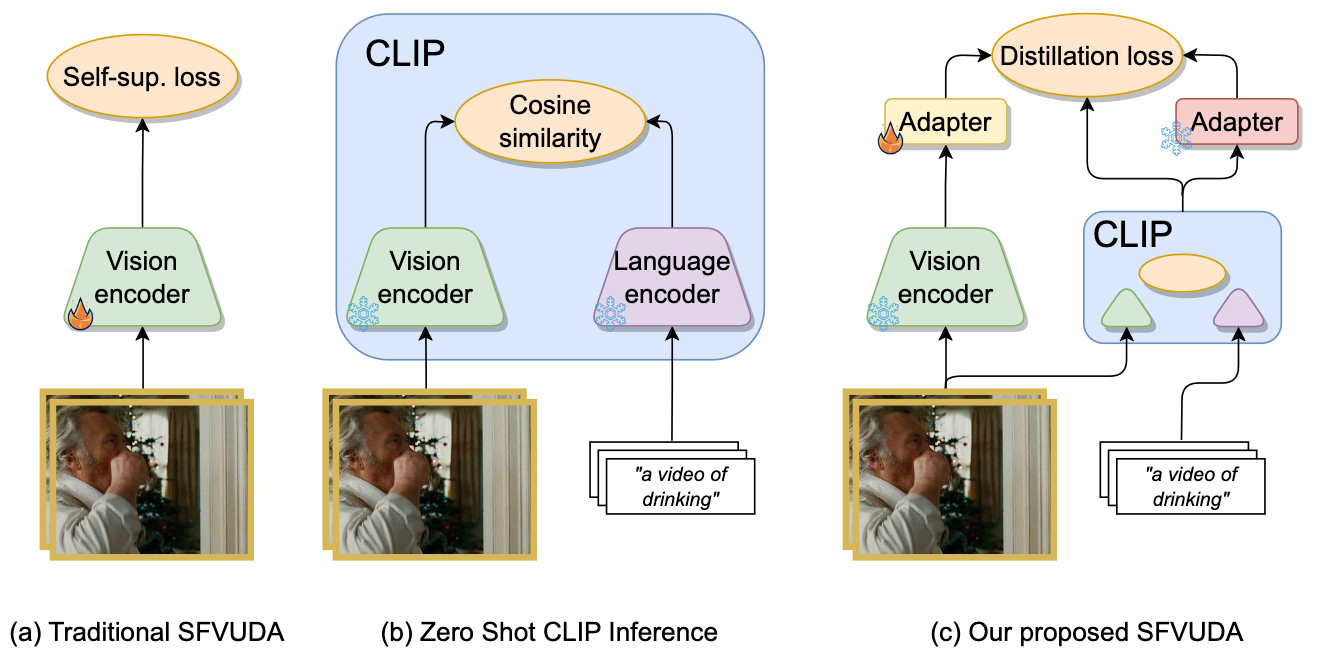
The Unreasonable Effectiveness of Large Language-Vision Models for Source-free Video Domain Adaptation
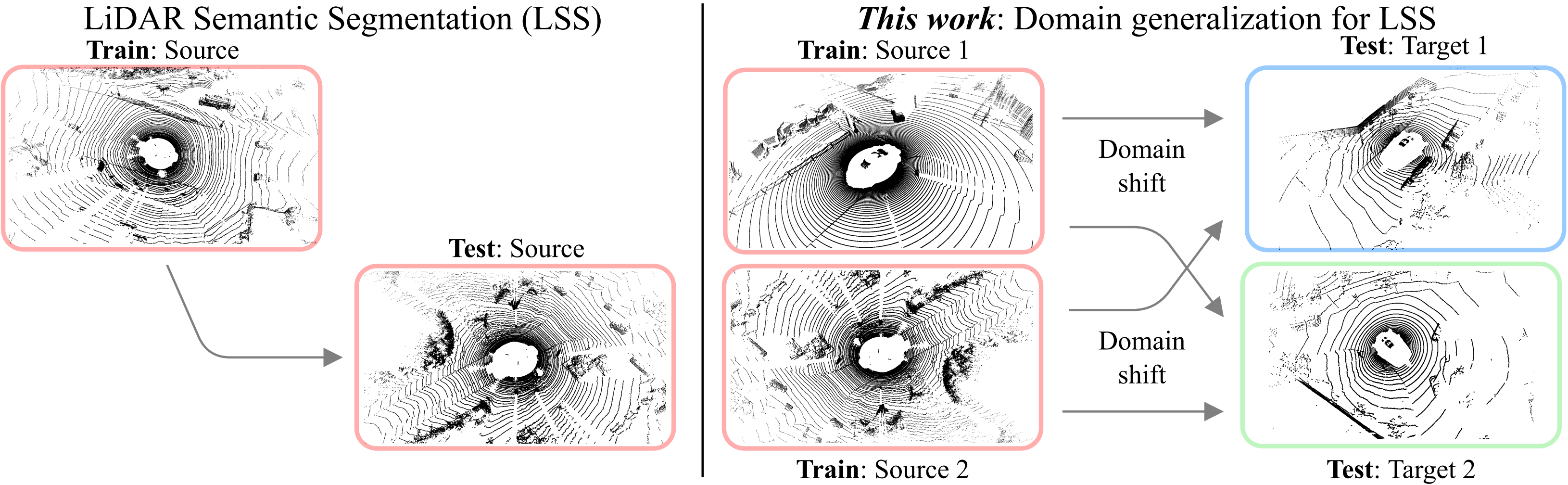
Walking Your LiDOG: A Journey Through Multiple Domains for LiDAR Semantic Segmentation
Cristiano Saltori, Aljoša Ošep, Elisa Ricci, Laura Leal-Taixé
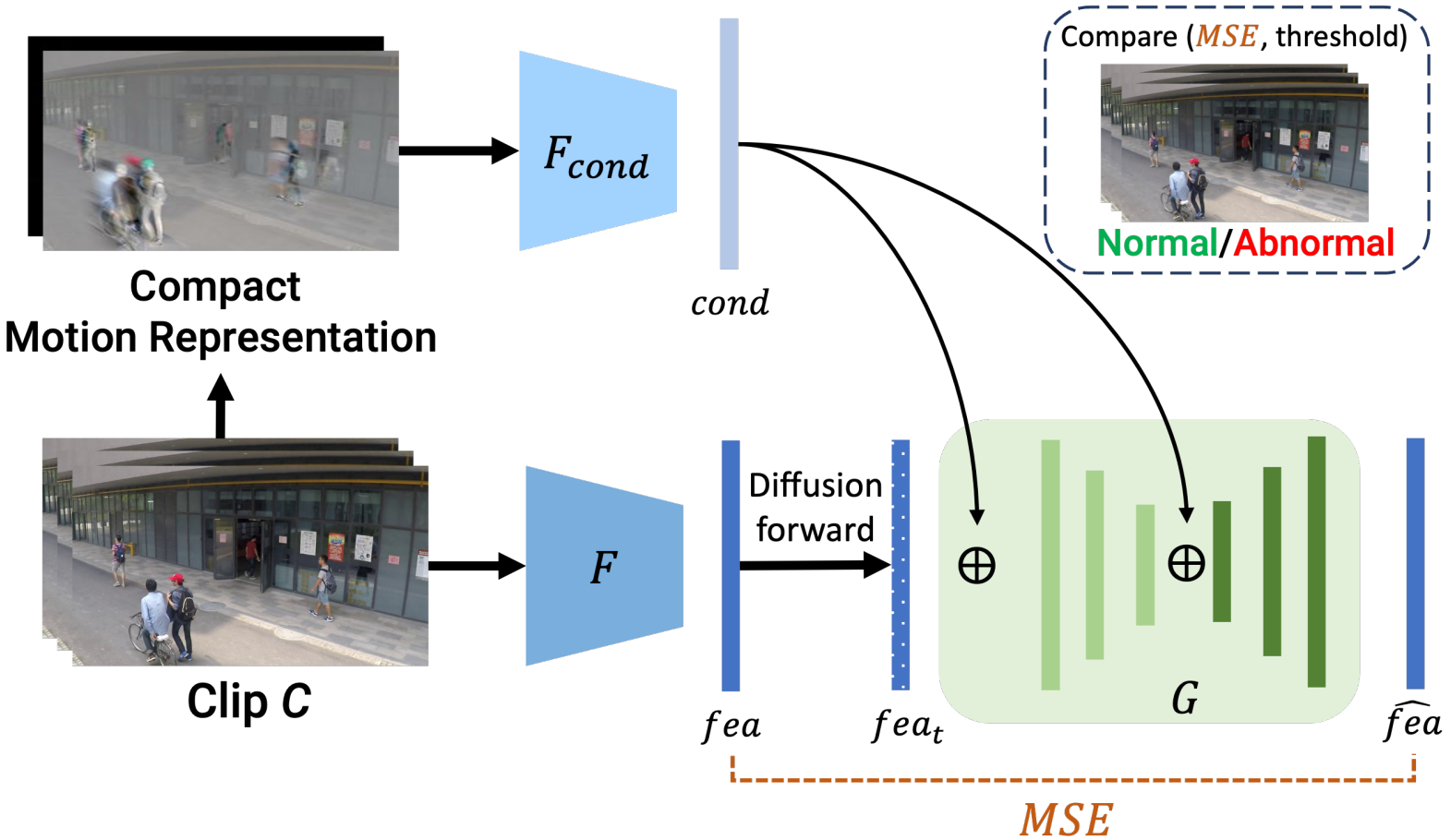
Unsupervised Video Anomaly Detection with Diffusion Models Conditioned on Compact Motion Representations
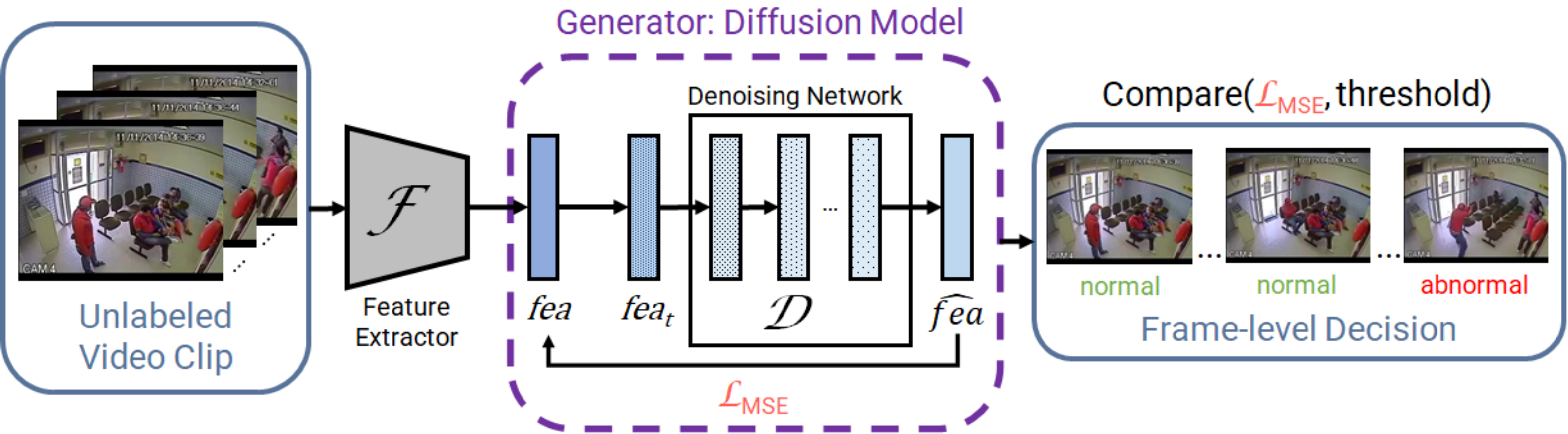
Exploring Diffusion Models for Unsupervised Video Anomaly Detection
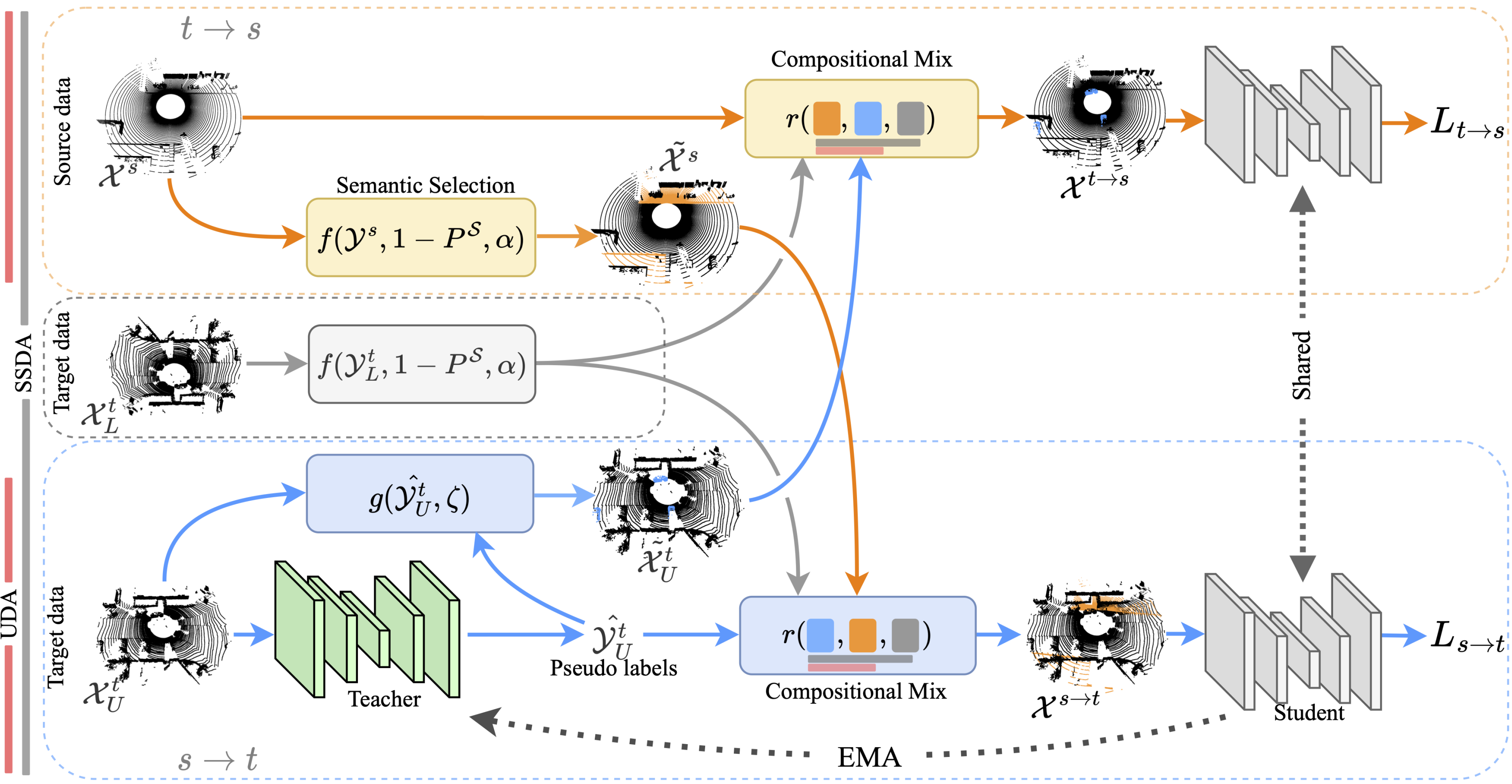
Compositional Semantic Mix for Domain Adaptation in Point Cloud Segmentation
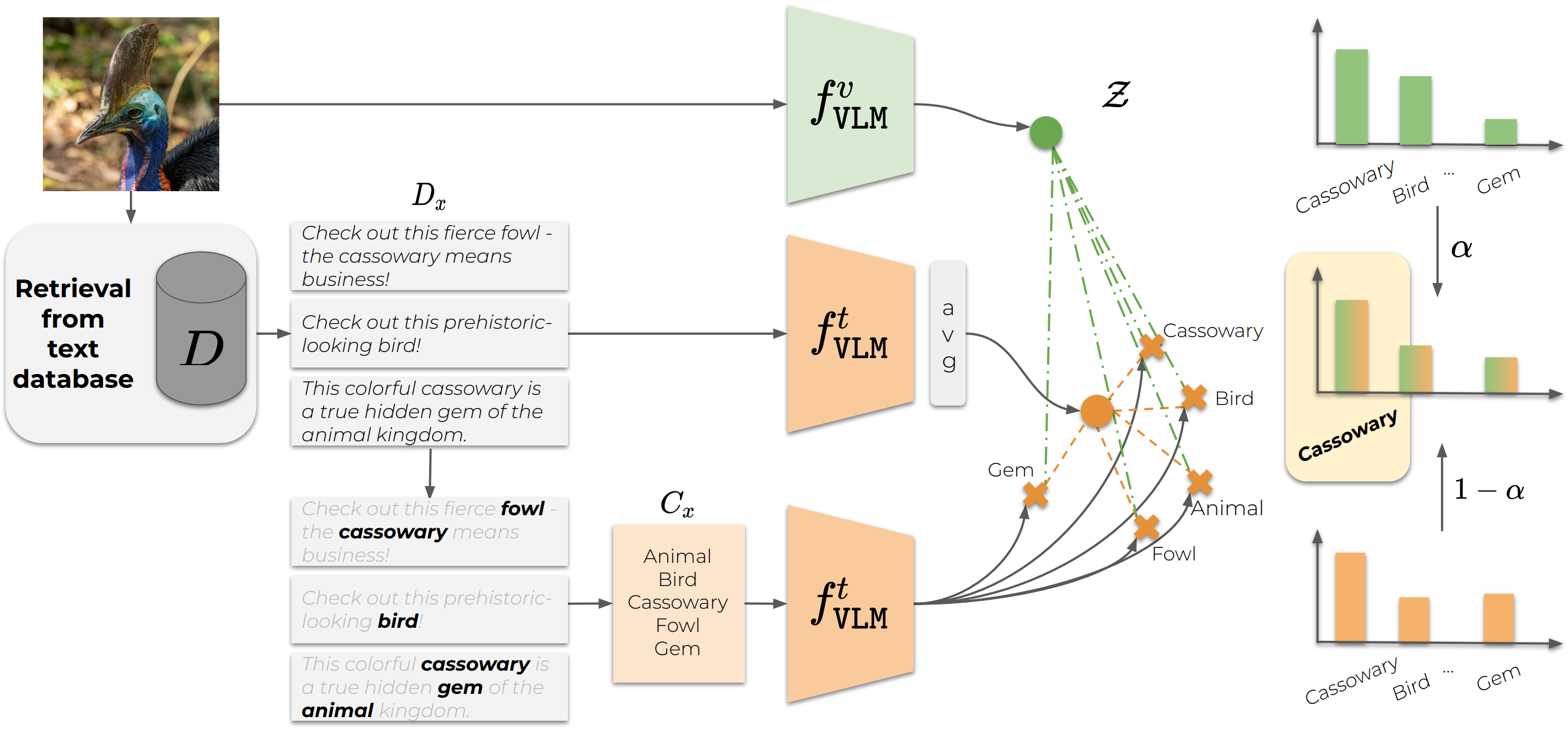
Vocabulary-free Image Classification
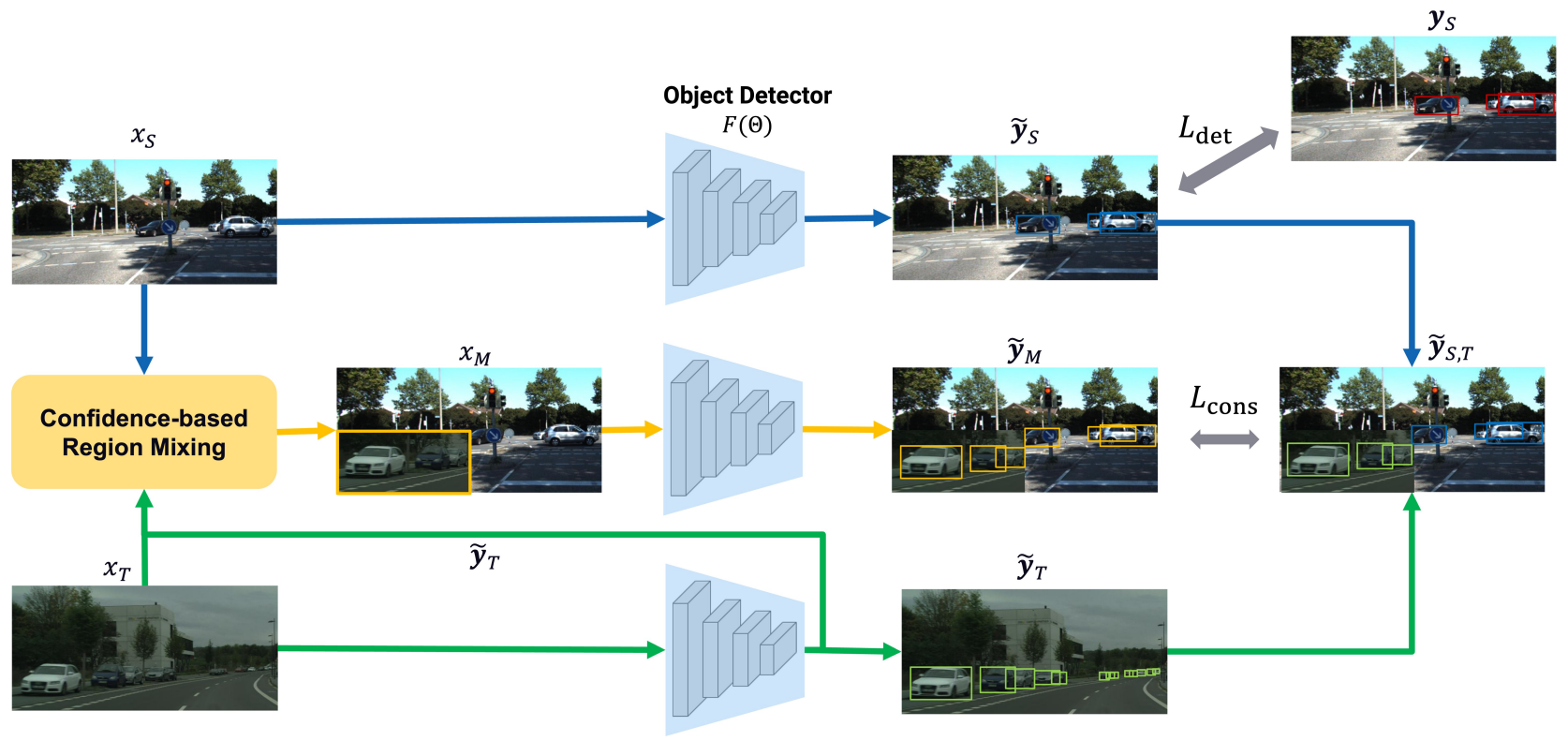
ConfMix: Unsupervised Domain Adaptation for Object Detection via Confidence-based Mixing
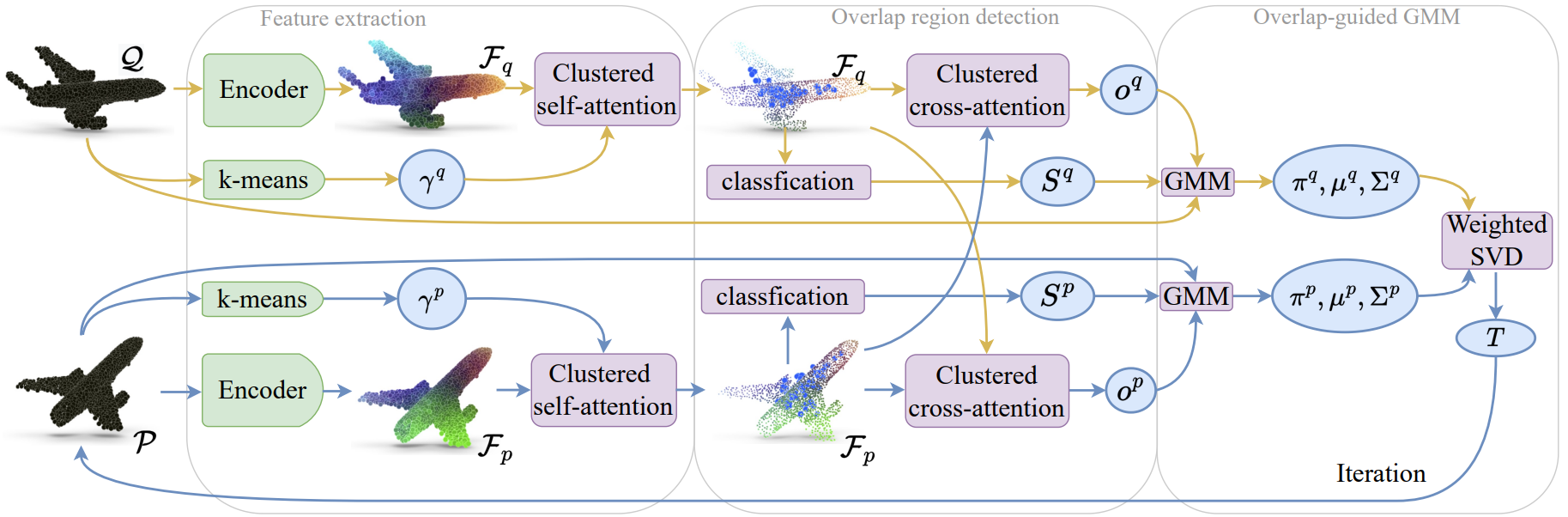
Overlap-guided Gaussian Mixture Model for Point Cloud Registration
2022
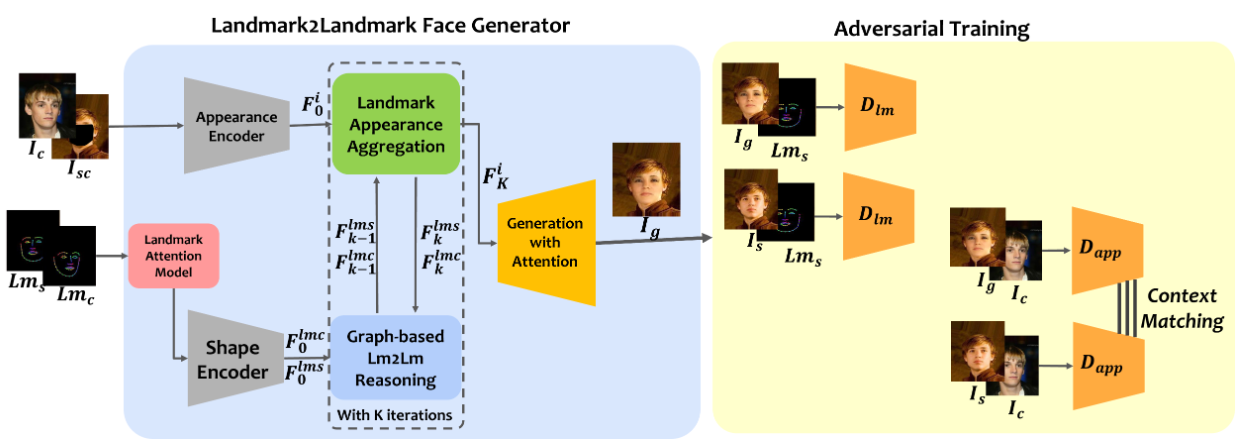
Graph-based generative face anonymisation with pose preservation
Cluster-level pseudo-labelling for source-free cross-domain facial expression recognition
Data Augmentation-free Unsupervised Learning for 3D Point Cloud Understanding
Playable Environments: Video Manipulation in Space and Time
Willi Menapace, Stéphane Lathuilière, Aliaksandr Siarohin, Christian Theobalt, Sergey Tulyakov, Vladislav Golyanik, Elisa Ricci
Self-Supervised Models are Continual Learners
Enrico Fini, Victor G. Turrisi da Costa, Xavier Alameda-Pineda, Elisa Ricci, Karteek Alahari, Julien Mairal
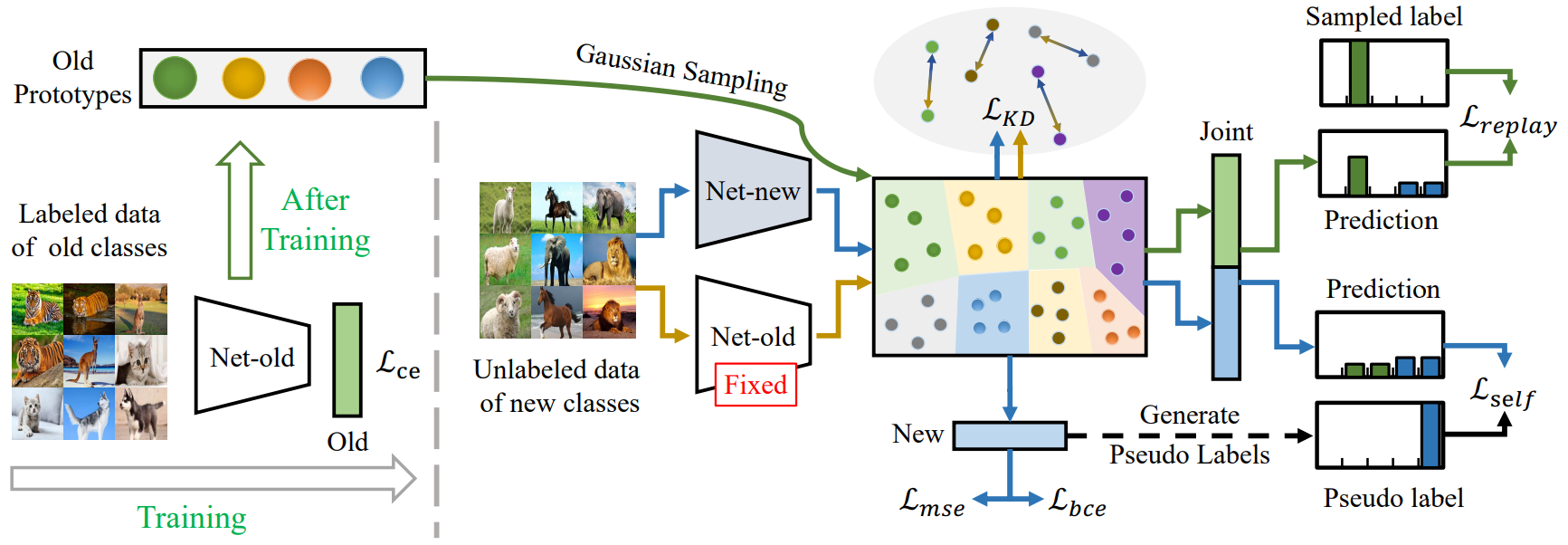
Class-incremental Novel Class Discovery
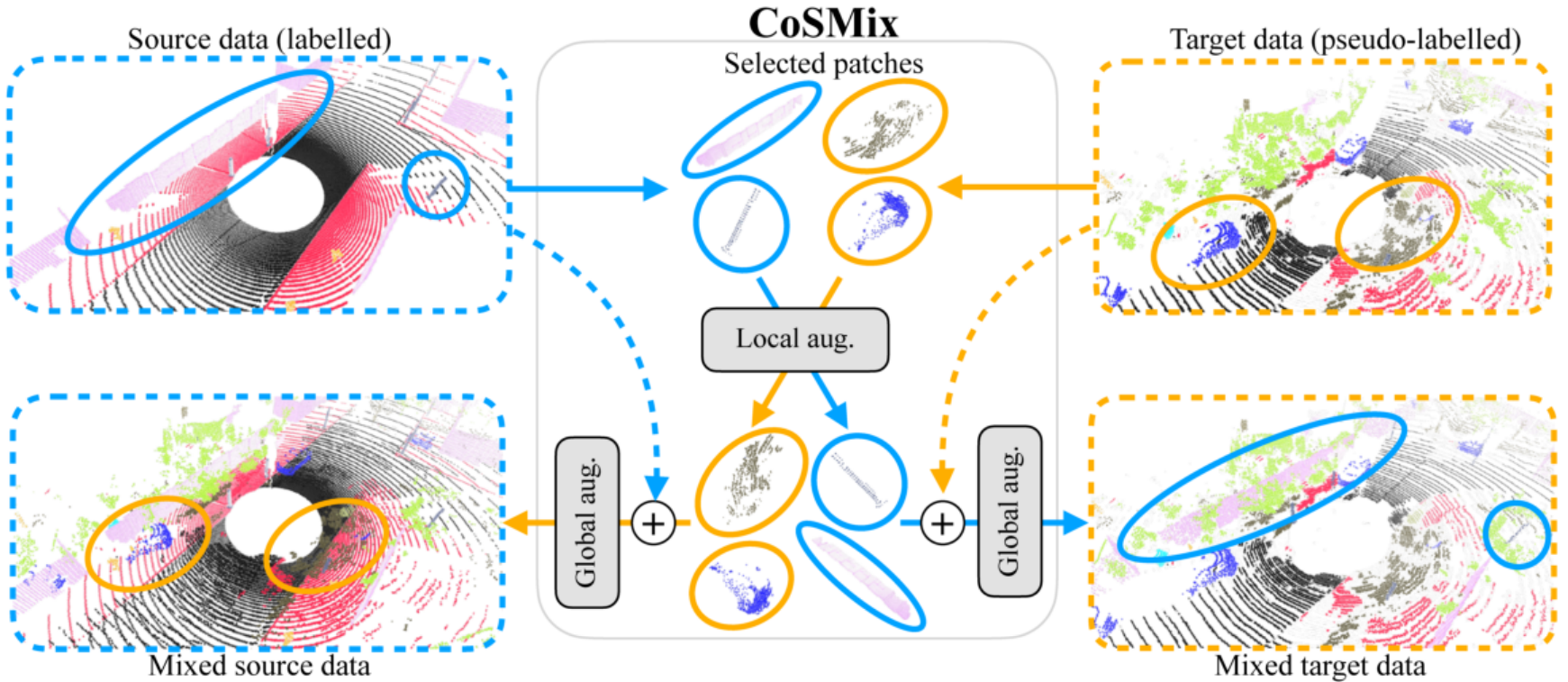
CoSMix: Compositional Semantic Mix for Domain Adaptation in 3D LiDAR Segmentation
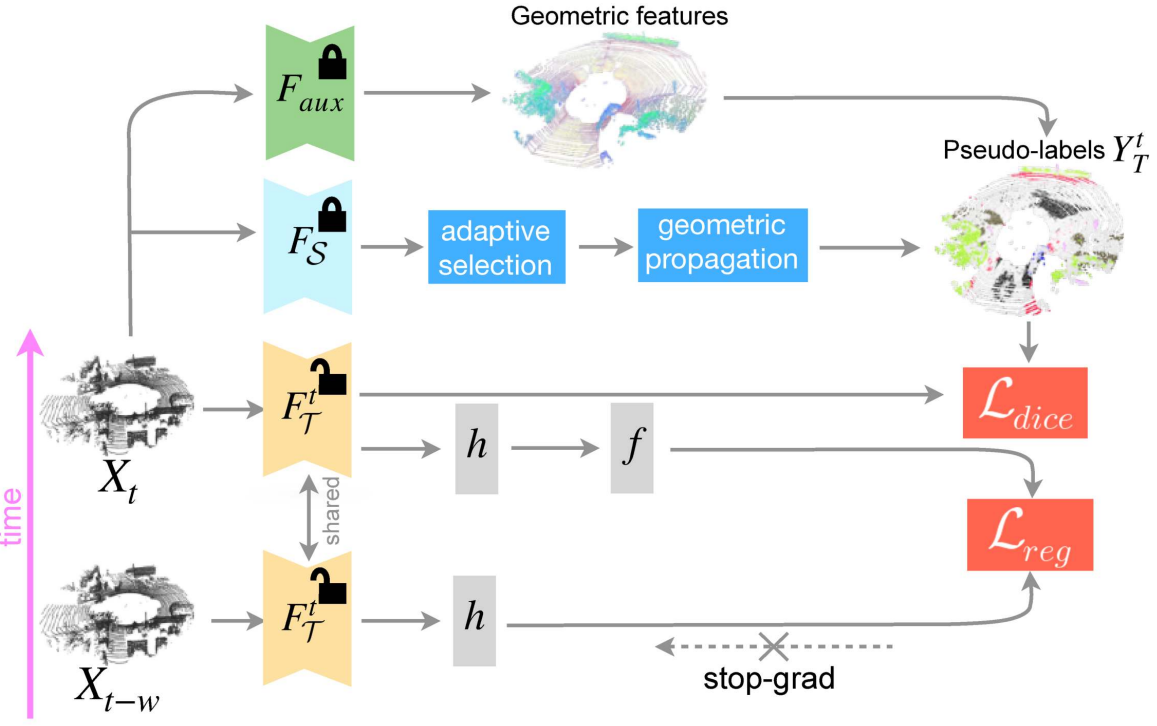
GIPSO: Geometrically Informed Propagation for Online Adaptation in 3D LiDAR Segmentation
Cristiano Saltori, Evgeny Krivosheev, Stéphane Lathuilière, Nicu Sebe, Fabio Galasso, Giuseppe Fiameni, Elisa Ricci, Fabio Poiesi

Quantum Motion Segmentation
Federica Arrigoni, Willi Menapace, Marcel Seelbach Benkner, Elisa Ricci, Vladislav Golyanik
Multimodal Across Domains Gaze Target Detection
Multimodal Emotion Recognition with Modality-Pairwise Unsupervised Contrastive Loss
Unsupervised Domain Adaptation for Video Transformers in Action Recognition
Victor G. Turrisi da Costa, Giacomo Zara, Paolo Rota, Thiago Oliveira-Santos, Nicu Sebe, Vittorio Murino, Elisa Ricci
Revisiting Viewing Graph Solvability: an Effective Approach Based on Cycle Consistency
Federica Arrigoni, Andrea Fusiello, Romeo Rizzi, Elisa Ricci, Tomas Pajdla
Variational Structured Attention Networks for Deep Visual Representation Learning
Continual Attentive Fusion for Incremental Learning in Semantic Segmentation
Guanglei Yang, Enrico Fini, Dan Xu, Paolo Rota, Mingli Ding, Hao Tang, Xavier Alameda-Pineda, Elisa Ricci
Multi-frame motion segmentation by combining two-frame results
Federica Arrigoni, Elisa Ricci, Tomas Pajdla
Uncertainty-aware Contrastive Distillation for Incremental Semantic Segmentation
Guanglei Yang, Enrico Fini, Dan Xu, Paolo Rota, Mingli Ding, Moin Nabi, Xavier Alameda-Pineda, Elisa Ricci
Dual-Head Contrastive Domain Adaptation for Video Action Recognition
Victor G. Turrisi da Costa, Giacomo Zara, Paolo Rota, Thiago Oliveira-Santos, Nicu Sebe, Vittorio Murino, Elisa Ricci
2021
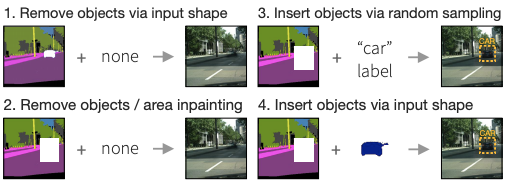
Semantic-Guided Inpainting Network for Complex Urban Scenes Manipulation
Pierfrancesco Ardino, Yahui Liu, Elisa Ricci, Bruno Lepri, Marco De Nadai
2020
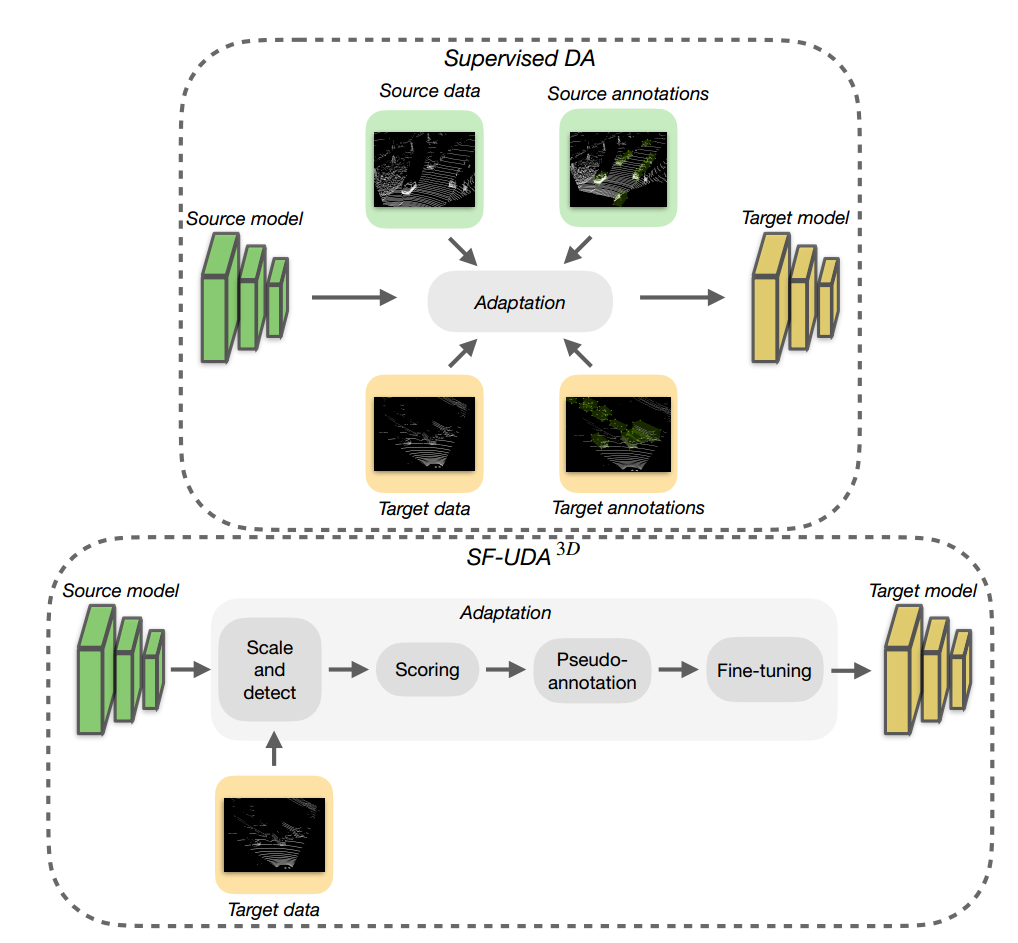
SF-UDA<sup>3D</sup>: Source-Free Unsupervised Domain Adaptation for LiDAR-Based 3D Object Detection
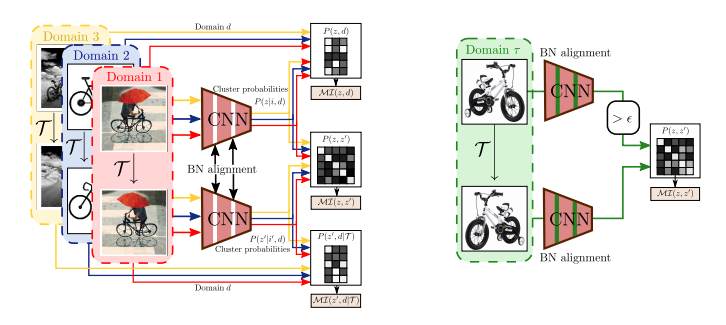
Learning to Cluster under Domain Shift
Willi Menapace, Stéphane Lathuilière, Elisa Ricci
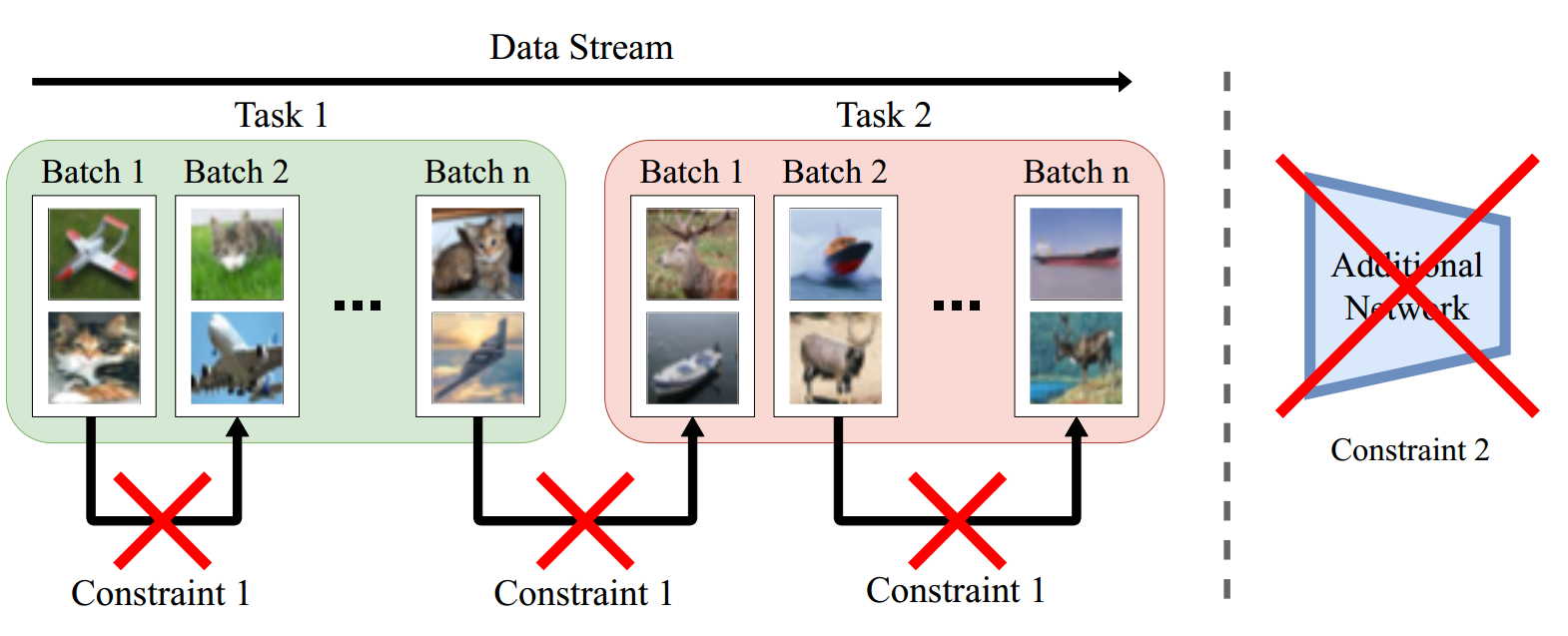
Online Continual Learning under Extreme Memory Constraints
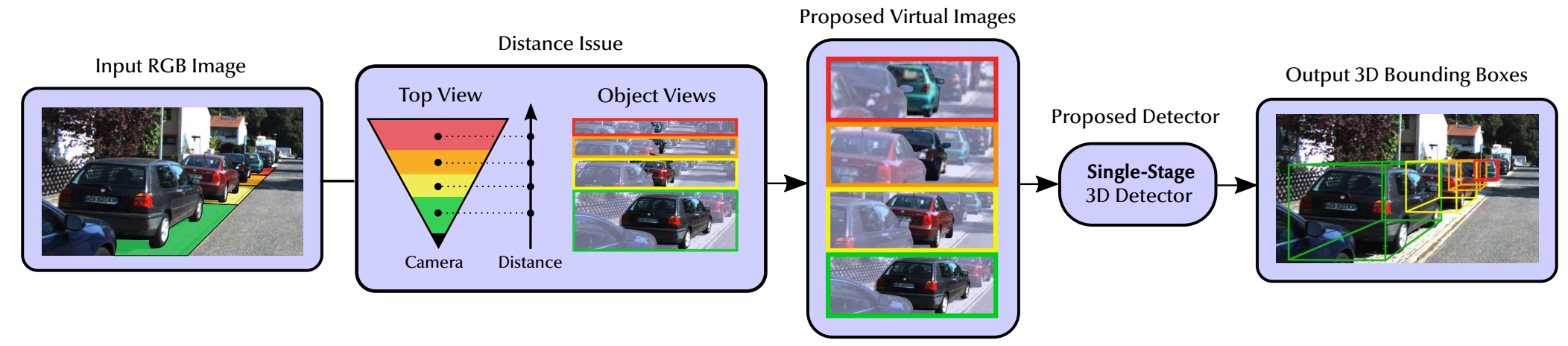
Towards Generalization Across Depth for Monocular 3D Object Detection
Andrea Simonelli, Samuel Rota Bulò, Lorenzo Porzi, Elisa Ricci, Peter Kontschieder
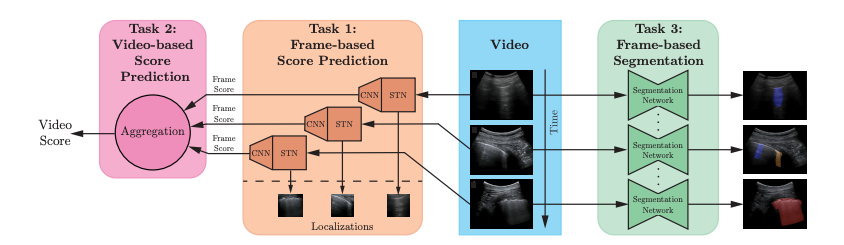
Deep learning for classification and localization of COVID-19 markers in point-of-care lung ultrasound
Subhankar Roy, Willi Menapace, Sebastiaan Oei, Ben Luijten, Enrico Fini, Cristiano Saltori, Iris Huijben, Nishith Chennakeshava, Federico Mento, Alessandro Sentelli, Emanuele Peschiera, Riccardo Trevisan, Giovanni Maschietto, Elena Torri, Riccardo Inchingolo, Andrea Smargiassi, Gino Soldati, Paolo Rota, Andrea Passerini, Ruud J G van Sloun, Elisa Ricci, Libertario Demi
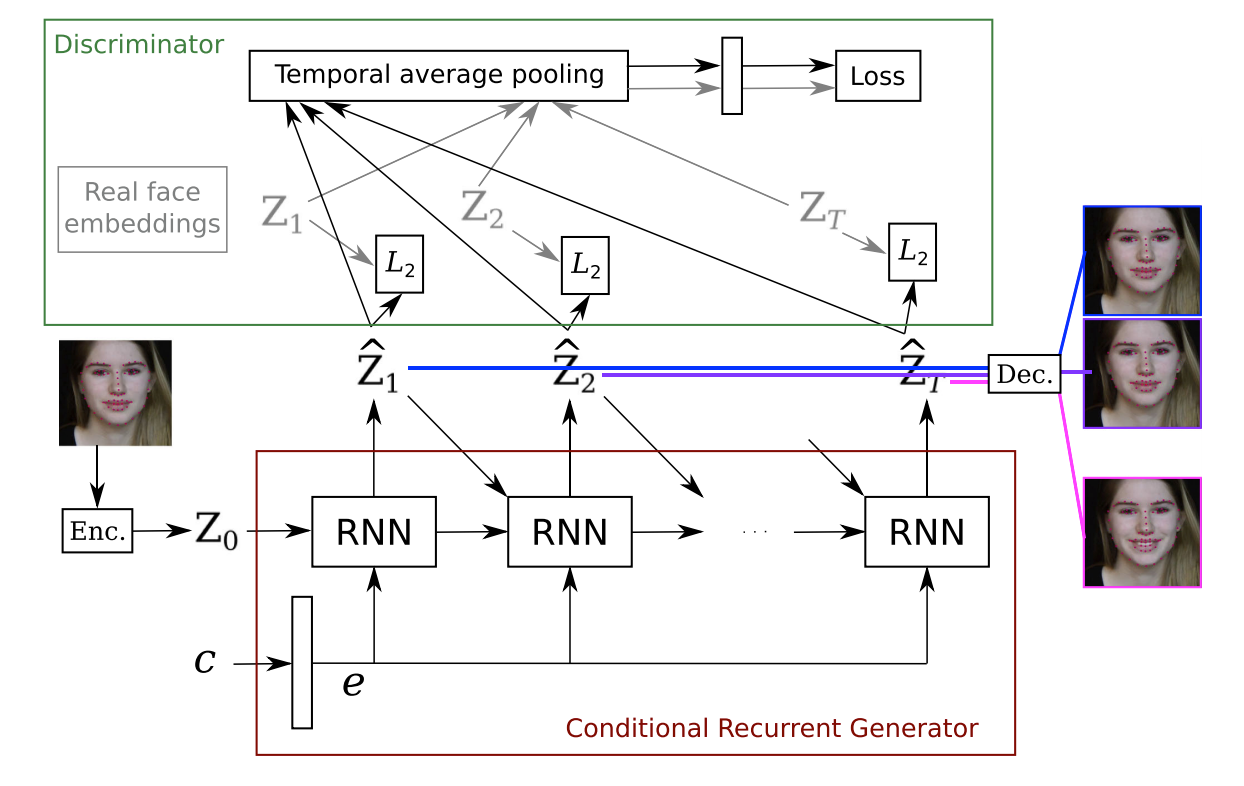
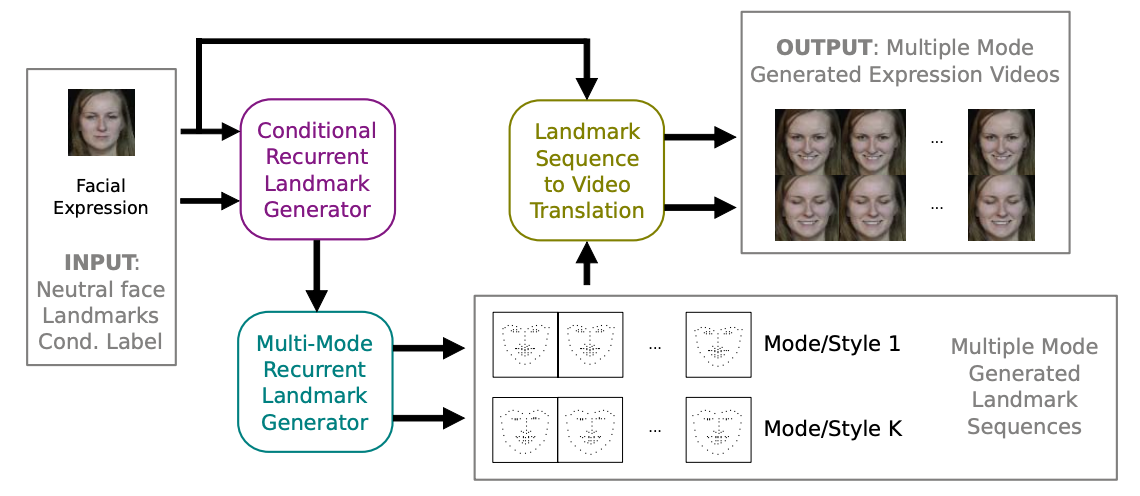
Learning How to Smile: Expression Video Generation with Conditional Adversarial Recurrent Nets
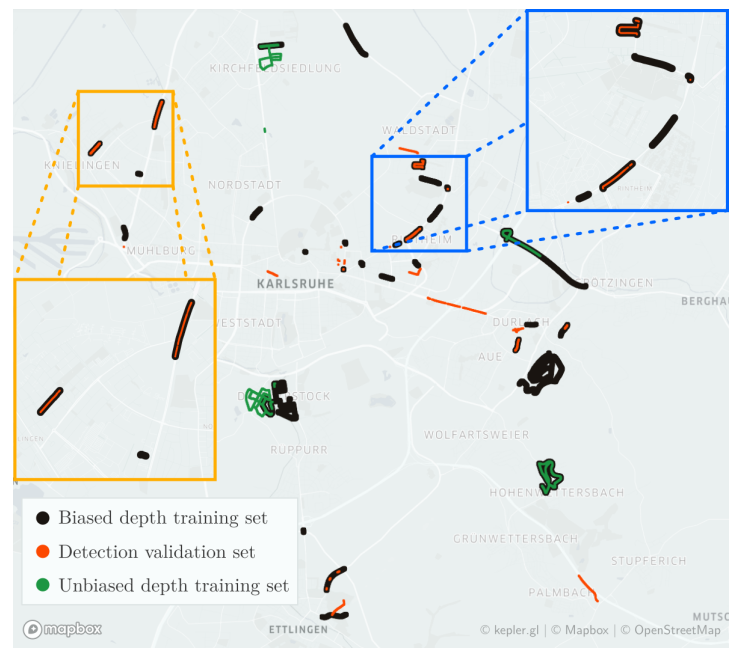
Demystifying Pseudo-LiDAR for Monocular 3D Object Detection
Andrea Simonelli, Samuel Rota Bulò, Lorenzo Porzi, Peter Kontschieder, Elisa Ricci
2019
Unsupervised domain adaptation using feature-whitening and consensus loss
2018